前言
2023 年 11 月标志着虚拟化格局的一个转折点。最初只是又一次备受瞩目的收购——博通对 VMware 的收购——迅速升级为一场颠覆,给全球 IT 社区带来了冲击。真正的冲击并非来自交易本身,而是 VMware 许可模式的突然而全面的变化。这些所谓的“许可地毯拉动”不仅让无数组织的成本飙升,还破坏了人们对曾经主导虚拟化市场的平台的长期信任。
这并非孤立事件。历史表明,许可模式的突然转变会造成普遍的不确定性和沮丧,常常让客户争相寻找替代方案。而在这些时刻,开源解决方案始终如一地成为最可行、最具未来保障性和最值得信赖的前进道路。
虚拟化格局发展迅速,随着企业抓住摆脱厂商锁定并使用云原生方法现代化基础设施的机会,许多企业正在超越 VMware。迁移到 OpenStack 已成为一种备受青睐的替代方案,可以提高灵活性、降低成本并确保 IT 环境的未来。
许多人深信不疑,下一个问题是:如何操作?需要多少成本?
转型并非一蹴而就。成功的迁移需要战略规划、合适的工具以及对技术和组织因素的深刻理解。由 OpenInfra 成员工作组开发的本迁移指南详细介绍了如何进行迁移,包括参考架构和生产案例研究。
从评估您当前的 VMware 部署到实施面向未来的云原生 OpenStack 解决方案,本迁移指南为 IT 领导者和技术团队提供了掌控虚拟化战略并构建真正现代数据中心所需的见解。
从 VMware 迁移到 OpenStack 不仅仅是切换,而是做出既无缝又具有战略意义的举动。在您采取这一步之前,您需要清晰地了解您的技术堆栈。哪些依赖关系可能会拖您的后腿?哪些工作负载现在可以迁移,哪些需要额外的规划?
本迁移指南是您通往成功的路线图。我们将帮助您提前识别潜在的挑战,为任何复杂的依赖关系制定策略,并确保顺利过渡到开放、面向未来的云。没有意外。没有挫折。只有一次执行良好的迁移,让您掌控一切。
开放技术推动着不懈的创新,使您能够无障碍地集成尖端工具。通过利用全球开源社区的力量,您可以访问经过实战检验的软件、专家见解和持续改进——所有这些都无需许可费用。
虚拟化的未来是开放的。您准备好采取行动了吗?
Jimmy McArthur,OpenInfra 业务发展总监
Linux 基金会
迁移到开源的优势
摆脱专有锁定并利用
像 VMware 这样的单一厂商虚拟化平台成本高昂。昂贵的许可费用、严格的合同以及旨在让您被锁定的专有功能使创新和按您的条款进行扩展变得更加困难。更糟糕的是,对特定厂商工具的依赖会造成不必要的复杂性,使未来的迁移成为一项代价高昂的难题。
使用 OpenStack,您可以消除厂商锁定并利用全球互操作性、开源解决方案生态系统。博通的价格模式变化已大大增加了 VMware 的年度运营成本——当您处于厂商拥有这种杠杆作用的地位时,这种情况很容易再次发生。使这一整类问题消失的最可靠和最全面的方法是采用 Linux 和 OpenStack 等开源软件平台。
通过切换到 OpenStack,您可以摆脱这些限制并拥抱开源的力量。没有限制性许可。没有强制升级。只是对您的基础设施的完全控制。OpenStack 的开源云生态系统使您能够优化成本、提高效率并选择在何处以及如何运行您的工作负载——无论是在内部还是与全球支持 OpenStack 的众多厂商之一合作。如果您的初始提供商不能满足您的需求,OpenStack 的互操作性允许您无缝切换到另一个厂商,而不会出现停机时间。
您的基础设施的未来应该掌握在您手中,而不是由厂商控制。
当您采用纯开源平台时,没有任何厂商可以夺走您的运营环境。无论您选择单枪匹马还是与合作伙伴合作,开源都让您完全拥有您的 IT 基础设施。
利用 OpenStack 的开放设计释放创新
按您自己的方式构建您的云
为什么要遵循厂商的路线图,而不能创建您自己的路线图?OpenStack 的开放设计理念为您提供了无与伦比的架构灵活性,可以构建适合您独特需求的云。
使用 OpenStack,您的 IT 团队可以自由地自定义基础设施的每一层,无缝集成最新的技术,并无限扩展。无论您需要高性能计算、边缘部署还是混合云解决方案,OpenStack 都能适应您的业务,而不是相反。
而且您可以忘记一刀切。使用 OpenStack,您可以根据自己的条款制定云战略并以自己的节奏发展,而不会受到厂商限制的阻碍。
您的云。您的规则。
您掌控的强化安全
在专有生态系统中,您的安全取决于厂商的发布计划。借助 OpenStack 的透明、开放开发模式,您将掌控一切。审核代码,立即实施安全补丁,并为改进做出贡献,而无需等待厂商批准。这种主动方法消除了盲点,加强了安全性,并确保您的基础设施始终能够抵御新兴威胁。
全球社区驱动的无情创新
与新功能以厂商的速度涓涓细流的封闭平台不同,OpenStack 蓬勃发展于持续的、社区驱动的创新。全球成千上万的企业、研究人员和开发人员合作突破界限,以比任何专有系统都快的速度提供尖端进步。没有停滞,只有不断发展,确保您的云始终走在时代前沿。
无缝集成与面向未来的敏捷性
厂商锁定将企业困在僵化的生态系统中,使现代化成为一项代价高昂的挑战。OpenStack 基于开放标准,可以与 Kubernetes、Ceph、Ansible 和最新的云原生技术无缝集成。这种级别的互操作性让您能够适应、扩展和发展——而无需代价高昂的迁移或兼容性问题。
通过拥抱 OpenStack 和 OpenInfra 基金会的“四开放”——指导原则,您的组织将获得无与伦比的自由、成本效益和为未来而构建的云战略。
VMware 功能与 OpenStack 的比较
OpenStack 和 VMware 共享比最初想象的更多相似之处。虽然这两个平台都提供许多相同核心功能,但它们使用不同的术语和架构框架来组织和呈现这些功能。这些结构和命名的差异通常会夸大它们真正有多不同的感知。
大多数核心计算、网络和存储功能在两个平台上几乎相同,反映了它们的成熟度和对多年经验和最佳实践的坚持。但是,它们的表示和架构是它们最大的不同之处
- OpenStack 技术更加离散——由多个项目(Nova、Neutron、Cinder、Horizon 等)组成的微服务集合,
- VMware 更具整体性,所有内容都集成到大型堆栈(vCenter、vCD)中。
大多数感知的差异源于术语。VMware 具有强大的品牌,具有 vMotion、vSAN 等术语。OpenStack 具有命名项目,这些项目不一定表明其功能(Nova → 虚拟化、Neutron → 网络等),或者对功能使用更通用的术语(OpenStack 中的“实时迁移”与 VMware 中的“vMotion”)。较少但仍然明显的差异归因于 OpenStack 是开源的,而 VMware 是专有产品套件。一旦您克服了这些差异,就清楚地表明,无论您选择哪个平台,大多数相同的功能都可用。
基本功能
计算比较


网络比较
存储比较
OpenStack 具有但 VMware 没有的功能
VMware 迁移框架
经济因素
构建虚拟化策略需要在软件许可、硬件升级和专业人员的初始成本之间取得平衡。虽然虚拟化可以提高硬件利用率并减少物理基础设施需求,但节省取决于有效的资源管理和规模。长期的经济成功还取决于许可模式、支持成本以及适应不断变化的工作负载和业务需求的能力等因素。
OpenStack 是开源软件,使用该软件无需支付软件许可费或订阅费。自从被 Broadcom 收购以来,VMware 已经将其定价从单点购买模式调整为更全面的订阅模式。两个主要的定价层级(VCF 和 VVF)现在按每年每个 CPU 核心定价,某些功能(例如 vSAN)则在此基础上收取额外费用。此外,虽然 Broadcom 维护了一些价格较低的产品,但通常会受到限制以限制其适用性,并引导用户转向主要的 VCF 和 VVF 层级。使用 OpenStack 可以立即缓解 VMware 大量的许可成本。
支持 OpenStack 的成本结构也不同。VMware 仅包含名义上的提交支持案例的能力,除非达到最高层级(VCF)。这取决于从 VMware 购买的供应商,因为一些 VMware 合作伙伴/供应商会叠加支持。在大多数情况下,所有与供应商相关的 OpenStack 成本都基于正在管理的宿主机支持。有各种支持模式可用,但在大多数情况下,它们的成本低于 VMware 的许可费用,并且当您将支持或管理添加到 VMware 软件订阅时,这些成本节省可能会变得非常可观。
开源软件不仅运营成本更低,而且从专有平台迁移所获得的节省,在重新投资时可以立即产生效益。运营成本的降低足以吸收迁移成本,并在过渡期间仍然节省资金。通常,这可以立即产生运营节省,可以将这些节省重新投入到您的环境中,以实现应用程序现代化、硬件更新或提高员工知识水平。
避免厂商锁定时的企业级支持
从 VMware 等专有解决方案切换到基于开源的平台时,最大的担忧之一是支持的可用性和选择。幸运的是,OpenStack 提供了一个强大的支持生态系统,确保可靠性、持续更新以及来自社区的专家协助。
利用 OpenStack 等开源解决方案的组织可以受益于各种企业级支持选项,包括长期支持 (LTS) 版本和升级注意事项。
VMware 提供紧密集成的、由供应商控制的升级路径,而 OpenStack 遵循六个月的发布周期,这可能看起来令人望而却步,但它使组织能够灵活地使其环境适应及时的趋势和机遇。2023 年,OpenStack 社区还推出了 Skip-Level Upgrade Release Process (SLURP),允许组织在仍然受益于战略更新的同时,减少升级频率。 许多 OpenStack 供应商提供长期支持 (LTS) 和 Skip-Level Upgrade Release Process (SLURP) 功能。
即使有了所有这些选项,选择开源并不意味着您将独自踏上旅程;许多商业资源可用于帮助架构、升级、运营和培训。这些公司可以充当信息、培训、架构、最佳实践和参考的指南,从而使组织能够实现自给自足。
全球 OpenStack 社区和生态系统如何支持您的组织
OpenStack 拥有强大的全球贡献者社区,他们不断改进该平台。采用 OpenStack 的组织可以受益于
- 关于设置、配置和故障排除的全面、文档完善的资源。
- 一个活跃的开发者和用户社区,提供实时讨论、专家指导和共享最佳实践。
- 由社区贡献和 OpenStack 基金会推动的定期更新和安全补丁。
- OpenStack 的开源性质,允许组织根据自己的需求定制平台,摆脱专有供应商的限制。
虽然 OpenStack 是开源的,但组织可以从多个供应商处获得企业级支持服务,提供
- 部署、维护和故障排除的专业服务。
- 安全更新和长期稳定性,以确保可靠的基础设施。
- 托管 OpenStack 解决方案,适用于需要完全支持环境的组织。
与依赖于供应商控制的支持的 VMware 不同,OpenStack 提供企业支持和强大的参与社区,从而提供灵活性、成本效益和开放创新。
自动化
在当今快节奏的 IT 环境中,自动化不再是奢侈品或便利,而是速度和效率决定胜负的世界中的生存问题。从基础设施部署的那一刻起,自动化就塑造了资源的配置、扩展和管理方式。消除手动流程、优化资源利用率以及确保无缝可扩展性的能力定义了云平台的效率。正确的自动化策略可能意味着无缝可扩展性和持续灭火之间的区别。
那么,OpenStack 和 VMware 在自动化方面有何不同?OpenStack 和 VMware 采取了截然不同的方法——一个优先考虑灵活性和开放性,而另一个则强化了供应商锁定和昂贵的附加组件。
让我们来看看使 OpenStack 在自动化方面脱颖而出的关键优势
开放且灵活的自动化框架
凭借 OpenStack 的模块化和 API 驱动设计,团队可以集成强大的自动化工具,如 Ansible、Terraform、Heat、Rockoon 和 Kubernetes,而无需被锁定到单个供应商的生态系统中。
OpenStack Heat 服务支持重用为 AWS 编写的现有 CloudFormation 堆栈文件。
经济高效且无供应商锁定
OpenStack 的自动化工具是开源的,减少了对昂贵专有软件的依赖。组织可以构建和定制其自动化堆栈,而无需产生额外的许可费用,从而实现显著的成本节省。
可扩展性和自愈能力
OpenStack 自动化支持动态自动扩展和自愈机制,确保工作负载得到有效分配,并从故障中自动恢复。VMware 提供自动化,但通常需要额外的付费解决方案才能获得类似的功能。
基础设施即代码 (IaC) 集成
OpenStack 原生支持基础设施即代码 (IaC),通过 Heat 和 Terraform 等工具实现,从而通过声明式配置文件实现完全的基础设施自动化。VMware 提供了一些 IaC 支持,但由于其对专有解决方案的依赖,灵活性较差。
控制和定制
OpenStack 用户可以完全控制自动化逻辑、工作流程设计和工具选择,从而实现量身定制的自动化策略。虽然 OpenStack 提供对自动化的完全控制,但 VMware 将用户锁定在其生态系统中,需要额外的许可并限制定制选项。
OpenStack 提供高度灵活、经济高效且与供应商无关的自动化框架,使其成为寻求可扩展性、控制和开放集成的组织的更佳选择。另一方面,VMware 虽然提供自动化,但成本更高、存在供应商锁定,并且适应性有限。对于希望实现敏捷性、成本效益和完全控制其云自动化的公司来说,OpenStack 不仅仅是一个选项,更是一个更具未来保障的解决方案。
迁移工具和解决方案
有几种方法和工具可以促进迁移过程。这些包括开源和自定义迁移解决方案,例如
- Coriolis by Cloudbase Solutions
- CONTRABASS Legato by Okestro
- FishOS MoveIt from Sardina Systems
- MigrateKit from VEXXHOST, Inc. (open source)
- Mirantis Migration Service
- OS-Migrate Ansible collection (open source)
- virt-v2v (open source)
- ZConverter
- vJailbreak (open source)
网络模型
OpenStack 支持各种网络技术,可用于构建用户弹性且可扩展的网络架构。
自助服务是大多数 OpenStack 功能的核心,网络也不例外。通过利用虚拟路由器和 VXLAN 和 GENEVE 等技术进行网络分段,项目中的用户可以创建和管理自己的网络,而无需传统网络运营团队的过多协助。在此模型中,用户可以通过将浮动 IP 分配给实例来直接连接到虚拟机实例,从而实现 1:1(公网到私网)静态 NAT。用户还可以将虚拟机实例隔离在负载均衡器后面,并限制对 bastion 或 jump host 以及自动化的访问。
OpenStack 还可以以更传统的“网络管理员”驱动模式运行,其中 VLAN 预先连接到主机,虚拟机实例配置为使用一个或多个网络,利用物理网络设备网关,例如路由器或防火墙。在此模型中,OpenStack 仍然可以为用户提供 DHCP 服务,但网络和子网的创建和管理取决于物理网络配置。
灵活性是 OpenStack 网络的核心概念。Neutron,网络服务,为 SDN 后端提供了一个抽象层,可以根据其功能进行选择。这样,Neutron 允许创建复杂网络架构和解决方案,例如服务链、BGP 设置或其他功能,具体取决于 SDN 解决方案。
存储
Ceph 和 OpenStack
Ceph 是 OpenStack 最常用的存储后端。Ceph 是开源软件定义存储,利用商品硬件提供企业级块、对象和文件存储,所有存储都来自统一的系统。Ceph 与 OpenStack 存储服务紧密集成,为 Nova 提供临时存储,为 Glance 提供镜像存储,为 Cinder 提供持久块存储,为 Swift 提供与 S3 兼容的对象存储,为 Manila 提供网络附加存储 (CephFS、NFS、CIFS)。Ceph 是一种成熟的企业级存储后端,已被证明适用于所有规模,从小型家庭实验室到多数据中心全球云基础设施。
Ceph 为 OpenStack 的独特亮点是它为 VM 提供写时复制的稀疏配置,从而实现非常快速的 VM 实例化,并减少存储空间和网络流量。
Ceph 和 OpenStack 共同提供了一套完整的现代存储服务和管理功能,使组织能够快速为用户部署功能齐全的本地云。
Ceph 突出显示的特性
数据保护:Ceph 使用复制或擦除编码来保护数据,并使用智能算法来构建耐用且高度可用的存储,同时考虑现实世界的故障域。通常建议对块和文件存储使用复制,而擦除编码可用于存档层和对象存储。两种数据保护类型可以共存于同一个集群中。在 2025 年秋季,Ceph 将推出一种高度优化的擦除编码后端,这将使 OpenStack 用户能够在不牺牲性能的情况下进一步降低成本。
直接数据访问:在 Ceph 中,客户端(例如虚拟机或交互式工作站)直接访问数据,而无需任何可能增加延迟或吞吐量瓶颈的网关。
自主自愈:Ceph 使用其对集群故障域(例如主机、机架、网络交换机等)的了解,以智能方式分配数据,以优化耐用性和高可用性。每当设备发生故障时,Ceph 会重新复制降级对象,以确保它们在最短的时间内完全耐用。
弹性:Ceph 集群具有高度弹性,可以根据需求增长或缩小,而无需进行代价高昂的迁移数据。硬件更换可以在不中断或与最终用户协调的情况下进行。
可扩展存储:Ceph 是一种水平可扩展的存储,只需添加更多节点,数据就会自动重新平衡,以提供增加的容量和性能。
多集群:Ceph 支持大型多数据中心环境,包括扩展集群(跨 2 个或多个数据中心的 1 个集群)、复制(跨区域的镜像/卷复制)、备份和其他方法。所有这些灵活性都已部署在无数环境中,以确保每个组织的业务连续性和灾难恢复需求得到满足。
Ceph 设计注意事项
Ceph 是一个高度灵活的系统——由于它将作为您的 OpenStack 云的耐用骨干网络多年,因此确保您的 Ceph 系统架构能够满足您在功能兼容性、成本、性能和增长方面的独特要求至关重要。
Ceph 项目维护全面的文档,供初学者入门以及经验丰富的操作员优化 Ceph 或执行常规维护。
Ceph 社区对新老用户都非常活跃和乐于助人。有关社区 Slack 频道、邮件列表和活动日历的信息在此处。
Ceph 基金会是一个非营利基金,通过各种宣传活动支持 Ceph 项目。其成员中的许多人提供 Ceph 的商业支持和专业服务。查找更多信息。
其他存储
除了 Ceph 之外,许多存储设备与 OpenStack 持久存储 (Cinder) 兼容。Cinder 同时支持多个后端,这些后端由在创建卷时给定的卷类型控制。例如,Cinder 可以同时具有 Ceph 和 SAN 后端。这允许重用现有的 SAN 设备,以及为特定目的添加设备。 大多数 SAN 风格的设备(iSCSI、FC、NVMeoF)都具有 OpenStack 驱动程序。功能集取决于各个驱动程序,但大多数设备都支持支持 Cinder 功能集所需的必要功能。
现有的 SAN 驱动程序不支持 OpenStack Nova 或 Glance。虽然可以将 Glance 运行在 Cinder 上,但当前的实现存在一些缺点。在大多数情况下,如果使用 SAN 作为持久存储,则为临时存储和镜像存储拥有 Ceph 集群是有意义的。
OpenStack 文档和存储设备制造商的手册提供了有关配置和功能集的更多信息。
存储加密
OpenStack Nova 和 Cinder 可以借助密钥存储 Barbican,直接在计算节点上加密块存储。如果配置了此功能,数据在离开虚拟机时会立即加密,并在返回虚拟机时解密,从而在传输和静态时都受到保护。在同一个云中可以同时存在加密和未加密的卷类型,这样对于不需要加密的数据,可以存储为未加密形式,以最大限度地减少加密算法对 CPU 的消耗。
备份与恢复
虽然云实例通常应尽可能无状态——最佳实践建议备份应用程序而不是实例本身——但现实往往并非如此。用户经常将云实例视为传统的虚拟机,手动更改其状态。因此,对 VM 级别进行备份的需求显而易见,我们将在以下部分中对此进行分析。
保护数百甚至数千个虚拟环境通常会使基于代理的解决方案变得难以管理。必须为每个需要保护的应用程序安装和维护代理。当然,在某些情况下——例如数据库——部署代理可能是必要的,但通常情况下,应尽可能避免基于代理的方法。
实例,就像任何其他虚拟环境一样,通常由两个主要组件组成:元数据和数据。元数据——即实例配置(CPU、存储、网络等)——由各种 OpenStack 服务提供,例如 Cinder 提供存储定义,Nova 提供计算资源。备份解决方案必须始终连同数据一起捕获元数据,以确保实例的一致视图;否则,您可能会发现后来附加的卷未包含在您的备份中。
关键要素是数据本身,它驻留在 OpenStack 卷上。OpenStack 支持多种卷类型,包括临时(短暂)卷、Nova 卷和 Cinder 卷。短暂卷可以安全地从备份中排除,而 Cinder 卷——包含持久应用程序数据——必须始终受到保护。但是,在某些罕见情况下,用户可能会不知不觉地将重要数据存储在 Nova 卷上,因此在必要时将它们包含在您的保护策略中是明智的。
磁盘附加备份策略
根据您的存储配置,您可能需要采用不同的策略来备份实例。在最简单和最常见的情况下,当您只有基于 Cinder 的卷并完全依赖 OpenStack 的核心 API 时,您可以使用磁盘附加方法。
此方法假定运行您的备份软件的辅助(代理)VM,它从受保护卷的快照中读取数据。虽然数据直接从底层存储读取,但 OpenStack 本身并不能跟踪自上次备份以来哪些块已更改。因此,备份应用程序必须扫描整个卷以查找已修改的块。
但是,如果您将 Ceph 作为后端,则可以利用 Ceph RBD 快照差异 API。在这种情况下,您仍然像使用磁盘附加方法一样将卷快照挂载到代理 VM 上,但不是读取每个块,而是调用 RBD API 以直接从 Ceph 监控器检索自上次快照以来的更改。这需要访问监控器的网络权限,并保留先前的快照,以便 Ceph 可以计算差异。
一些供应商(包括 Storware)提供基于校验和的方法:他们将卷划分为固定大小的区域(例如 64 MiB),并比较备份之间的校验和。如果区域的校验和不同,则读取整个区域。虽然这会增加处理时间,但它可以在任何 Cinder 支持的存储上启用增量备份,而无需依赖 Ceph。
另一种更简单的替代方法是每次执行完全备份,并让去重层消除重复块,从而避免了增量备份的复杂性。
总而言之,磁盘附加策略涵盖了广泛的场景(包括非 Ceph 存储)。Cinder 为各种磁盘阵列提供了一个透明的抽象,虽然 OpenStack 缺乏内置的已更改块跟踪 (CBT),但您可以使用快照差异 API、校验和扫描或利用去重来近似实现它。
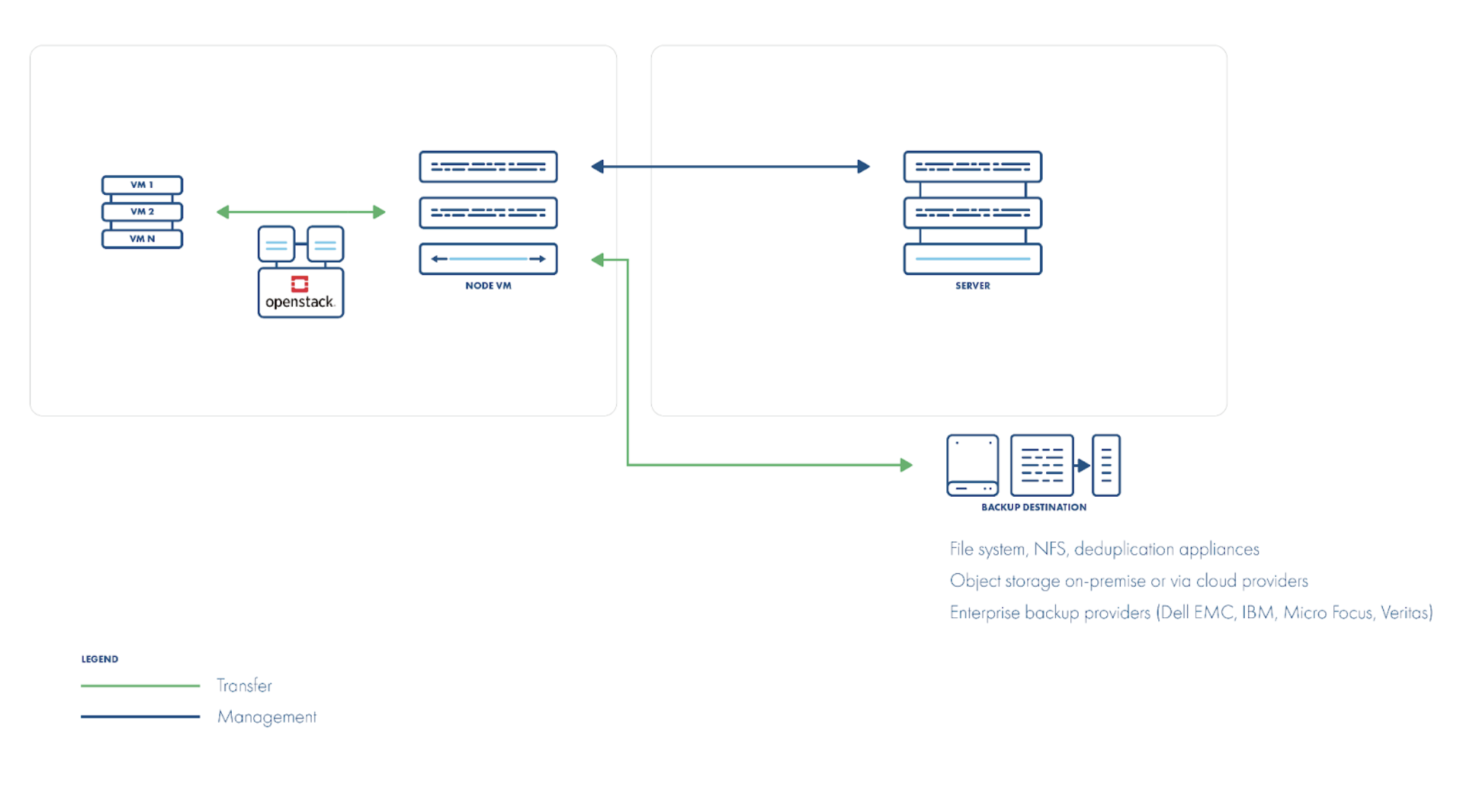
直接从主机/存储备份策略
磁盘附加策略无法解决的一个方面是备份 Nova 卷。虽然不建议将应用程序数据与操作系统放在同一个卷上,但有些用户仍然这样做。Nova 卷——为来宾操作系统配置——未通过 Cinder API 暴露,也无法像常规 Cinder 卷一样挂载。相反,它们通常作为 QCOW2 文件链存在于计算主机(或底层存储)上,需要直接访问才能进行备份。
直接传输策略在与磁盘附加不同的层上工作:它通过 libvirt 直接与 hypervisor 通信以定位和传输适当的 QCOW2 文件。快照也是直接在这些 QCOW2 镜像上拍摄的,而不是通过 API。但是,请注意,VM 在备份期间不应在主机之间迁移,因此 QCOW2-delta 快照只能简短保留。
可以使用 libvirt 的 dirty-block map 功能进行增量备份,该功能跟踪 VM 磁盘上已更改的扇区,而无需依赖快照。然后,您可以仅导出这些已更改的块(或执行完全导出)通过 libvirt 的内置备份命令,数据直接从主机流动。一个注意事项:对于非 QCOW2 磁盘格式,dirty-block map 仅在 VM 运行时跟踪更改;关机需要完全备份。
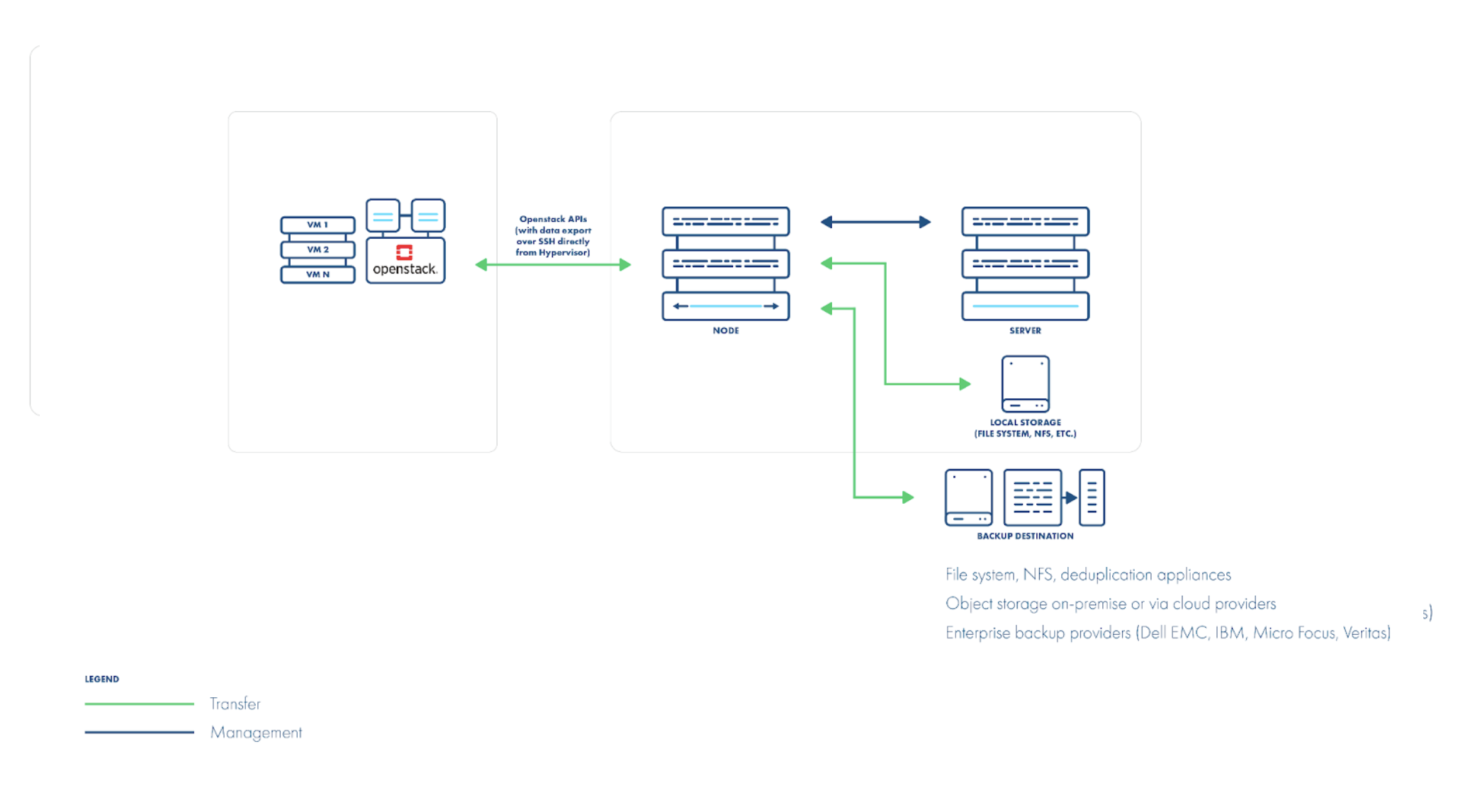
当您的后端是 Ceph RBD 时,您根本不需要 dirty-block map。您可以直接在 Ceph 中对 RBD 卷进行快照并流式传输,这比从主机读取 QCOW2 文件快得多。对于增量备份,您可以选择挂载 RBD 设备(通过 RBD 或 RBD-NBD)并仅读取已更改的块,或者利用 Ceph 的本机“diff”API 来获取增量数据而无需挂载。
一些备份供应商可能会建议在每个 hypervisor 上安装代理或软件。我们不建议这样做:特定于供应商的主机级别更改可能会破坏您的 OpenStack 发行版,或者在升级后变得不受支持。
无论采用何种策略,您都必须始终通过 OpenStack API 获取实例元数据。在恢复期间,您需要重新创建 OpenStack 实例,而不仅仅是 libvirt VM。在启动恢复的实例之前,您可能还需要将 Nova 卷导入 Glance(作为镜像)。
最后,请考虑如何处理跨数据中心的 VM 镜像。如果许多 VM 共享相同的基本镜像,您不希望为每个 VM 还原该镜像(浪费存储)。您的备份解决方案应检测镜像是否已存在,或者让您映射到替代镜像 ID(如果主数据中心的镜像不可用)。
如您所见,此策略不需要在客户机中部署代理:所有数据都通过网络从主机或存储传输到您的备份服务器。但是,您确实需要网络连接——以及适当的访问凭据——到您的 hypervisor 和存储系统。
备份存储
一旦实例数据和元数据被导出,就需要安全地存储它们。一个常见的起点是传统的的文件系统,它可能提供去重、快照或 reflinks 来构建一个合成备份存储库。
但是,在更大规模下,您通常需要一个更具可扩展性的后端——通常是对象存储。OpenStack 提供了一个专用的对象存储服务,称为 Swift,它还支持 S3 API。在实施过程中,您可以选择使用哪个 API 进行集成。
一个重要的考虑因素是对象大小限制:Swift 默认情况下将对象限制为 5 GB,因此即使是适度大小的磁盘也需要对象分段。
对象存储的一个不太明显的优势是,它可以充当所有数据移动器的单个备份目标。这使得可以从一个可用区或数据中心备份实例,并在另一个可用区或数据中心恢复实例,而无需传统文件系统的限制。
缺点是,恢复可能需要重建整个备份链,因为如果没有复杂的数据分块机制,则无法进行合成合并。
您还应考虑对象压缩,因为对象存储不支持稀疏磁盘,并且实例内的空闲空间可能会不必要地消耗大量容量。一些供应商为 Swift 提供内置压缩和数据分段功能,从而减少了实例大小的问题。
另一个需要评估的关键功能是支持合成合并——即使大多数运行是增量的,也能立即呈现一个完全合并的“完全”备份。朴素的方法——复制整个完全备份并覆盖增量数据——会消耗大量的存储空间,即使使用去重,也会强制您重写整个 VM 磁盘。
支持合成合并的供应商利用存储特定的技巧(快照、reflinks 或类似方法)来立即创建一个虚拟的完全副本,然后合并增量更改而无需复制未更改的数据。
即时恢复
即时恢复——在 VMware 环境中无处不在,但在 OpenStack 中仍然出现——允许您直接从备份存储挂载和启动 VM。这使您可以快速验证数据一致性并确认恢复实例内的应用程序是否实际启动。当您有数十甚至数百个 VM 需要测试时,这些即时恢复变得必不可少。
顾名思义,即时恢复必须真正“即时”。通常这意味着您的备份存储库需要按需呈现一个完全合并的镜像——通常通过合成合并——因此在恢复时没有合并延迟。
在 OpenStack 中,您可以定义一个指向备份供应商存储的自定义 Cinder 卷类型,以启用即时恢复。当您启动测试 VM 时,Cinder 会从该供应商支持的池中配置其卷,并且备份系统动态地将实时数据提供给实例。
不太明显的元数据需要处理
在 VMware 世界中,您通常只需要备份 VMX 文件,但在真正的云环境中,实例元数据分布在多个服务中。在恢复实例时,您必须重新创建其原始计算资源设置(“flavor”)。由于云标准化了实例大小,您的恢复解决方案应简单地从可用 flavor 中选择,而不是发明新的 flavor。
同样,实例应从集中式 OS 镜像重新构建。这些镜像是静态的,不包含用户数据,因此如果您正在恢复,例如,十个相同的实例,您应该引用现有的 Glance 镜像(如果仍然可用),而不是重新上传十次。
网络添加了另一层复杂性。将虚拟接口映射到正确的网络很简单,但 OpenStack 的安全组——VMware 端口组或防火墙规则的等效项——也必须重新创建或引用(如果它们已经存在于目标环境中)。
最后,请考虑 SSH 访问密钥。在 OpenStack 中,您通常无法导出私钥,因此强大的备份和恢复解决方案应允许您在恢复时指定管理密钥对。这样,即使原始密钥丢失,您也可以重新获得访问权限。
可扩展性
在构建大规模环境时,您还必须考虑备份解决方案的可扩展性。在可扩展的架构中,通常需要增长的组件是数据移动器,它处理实际的数据传输。为了支持更大的部署并同时运行多个备份作业,您可能需要——甚至需要——部署多个数据移动器。
从可扩展性的角度来看,重要的是检查您的供应商对并发任务或每个数据移动器可以运行的备份线程数量的限制。根据您的基础设施调整这些设置将有助于最大限度地提高吞吐量,而不会使您的系统过载。
在运行并发备份时,请记住扩展您的备份存储。更高的并行流数量——尤其是针对可扩展的后端(如 Ceph)——可能会在接收端创建一个瓶颈。
您可以通过在每个数据移动器上配置更大的暂存区域来缓冲数据,然后再将其发送到长期存储来缓解临时高峰。或者,使用具有高带宽连接的接收端的可扩展存储。请注意,对象存储通常会阻止合成合并,但您可以通过使用支持 reflinks 的文件系统(例如 NFS 4.2+)作为备份目标来解决此问题。
最后,请注意,磁盘附加方法受每个总线的 SCSI 设备限制,通常将同时导出限制为每个节点大约 25 个。在一个大型可用区中,这可能会成为一个瓶颈。但是,一些供应商允许您在每个主机上部署一个数据移动器,因此在一个 10 主机区域中,您可以运行十个数据移动器,每个数据移动器仅备份其自己主机上的 VM。
Horizon/Skyline 集成
在云环境中,多租户是一个基本考虑因素。OpenStack 的 Horizon 仪表板通过将每个租户隔离在其自己的项目范围内来强制执行这一点,因此用户只能看到属于其项目资源的资源。
一些供应商(包括 Storware)提供一个 Horizon 插件,该插件在仪表板中添加了一个备份选项卡。此插件尊重用户的当前项目上下文,并通过一个中间服务公开几乎所有备份操作,该服务将适当的 API 调用转换为并转发到供应商的后端。这确保了用户只能管理存在于其项目中的实例——或以前存在于其项目中的实例,例如在意外删除之前。
此插件允许用户定义备份策略和计划,并选择适当的备份目标。该插件的视图和 UI 结构与供应商的本机界面密切匹配,但可以直接在 Horizon 中访问。
对于托管服务提供商 (MSP),控制哪些项目可以看到某些工件至关重要。例如,您可能希望限制对备份策略、备份目标或恢复可用区的可见性。一些供应商允许管理员为这些项目配置项目级别的可见性设置。
备份配额
允许最终用户定义自己的备份策略——或运行频繁、重叠的备份——可能会对您的基础设施造成重大负载。为了控制这一点,您的备份解决方案应允许管理员设置配额并将其分配给各个项目。
配额可以包括备份和恢复操作的软限制和硬限制。达到软限制会生成警报,但仍允许作业继续进行;超过硬限制会阻止任何进一步的备份或恢复开始。
您可能需要限制每个实例或每个项目在给定时间窗口内的备份或恢复操作次数。或者,您可能更倾向于限制传输的总数据量,而不是操作次数。
备份 API
虽然备份 API 功能在现代解决方案中很常见,但并非一直如此。您最终需要访问备份供应商的 API,以触发备份、让解决方案发现新创建的实例、收集计费指标等等。
检查您的供应商是否记录了如何自动化他们的产品。虽然 CLI 对于简单的脚本来说很方便,但您应该期望并理想情况下需要一个 RESTful API,以便在选择项目的集成技术时获得最大的灵活性。
复制
对于您的虚拟机 (VM) 而言,灾难恢复 (DR) 功能对于任何关键任务型应用程序至关重要。为了在灾难恢复场景中提供从 OpenStack 到另一个 OpenStack 集群的 VM 无缝复制,有必要使用第三方解决方案,例如 Cloudbase Solutions 的 Coriolis。Coriolis 不需要安装任何代理到 VM 或平台,并且仅连接到必要的 OpenStack 服务。Coriolis 是使用一组 OpenStack 组件构建的,例如 Keystone、RabbitMQ 和 Barbican,并且可以与您的 OpenStack 环境完全集成。
通常,在 OpenStack 环境中复制数据可以通过多种方式实现。最基本的方法是使用存储基础设施本身,例如 Ceph 复制(或任何其他类型的存储级别复制)。但是,具有挑战性的部分是将复制的卷连接到之后需要创建的实例。
目前,很少有解决方案支持 OpenStack 环境的典型每实例复制场景,但您可以尝试使用现有的构建块来实现它。一种基本方法是使用备份软件执行完整和增量备份,将它们存储(或复制)到目标 OpenStack 环境附近,然后定期启动实例恢复。这种方法的主要缺点是,默认情况下,每次完整恢复时都必须传输大量数据。然而,优势在于,即使使用当前可用的解决方案,例如 Storware,您也可以使用其内置的批量恢复机制(有时称为“恢复计划”)。
在不久的将来,OpenStack 的解决方案将类似于 SRM (Site Recovery Manager),其中快照差异被复制到辅助位置,并且仅将差异(增量备份)应用于目标卷。这将解决大数据传输和漫长复制时间的问题,并可能在必要时提高 RPO(恢复点目标)。
可观测性
在云基础设施领域,您看不到的东西可能会伤害您。无论是性能下降、意外故障还是安全威胁,对系统健康状况有清晰的了解至关重要。
OpenStack 和 VMware 对可观察性采取了根本不同的方法,反映了它们整体的设计理念。OpenStack 优先考虑灵活性、定制化和开放标准,而 VMware 强调集成、供应商管理的解决方案。
让我们分解一下。以下是 OpenStack 与 VMware 中可观察性定义的一些关键区别。
开源与专有监控
OpenStack 使用 Prometheus、Grafana、Ceilometer 和 OpenTelemetry 等开源工具,使组织对其监控设置和集成拥有完全控制权。相反,VMware 是一个专有解决方案,具有附加组件——例如 vRealize Operations (vROps) 和 Aria Operations——需要额外的许可。这种方法迫使用户签订多个专有合同,增加了成本并降低了解决方案与第三方工具的灵活性。这种方法导致额外的许可,增加了成本并使其对第三方工具的灵活性降低。
灵活性和定制化
OpenStack 提供对遥测数据、仪表板和警报的完全控制,使其易于将监控调整到组织的需要。虽然 VMware 提供了内置监控,但定制化仅限于 VMware 的生态系统。
安全性和合规性
OpenStack 允许组织在本地托管监控工具,确保数据主权并符合安全策略。VMware 将日志和指标存储在 VMware 的生态系统中,这可能会限制某些行业监管合规性的灵活性。
对于寻求具有成本效益、灵活且高度可定制的监控解决方案的组织而言,OpenStack 提供了具有开源工具和广泛集成可能性的供应商中立的可观察性。VMware 虽然提供强大的监控体验,但会以更高的成本和有限的定制选项将用户锁定在其生态系统中。
通过选择 OpenStack,企业可以构建一个与他们的基础设施需求相符、高效扩展并避免供应商锁定的监控框架,从而确保其云环境的长期灵活性和控制力。
资源调度
有效地利用资源是云计算的核心原则,也是一种 OpenStack 资源调度的主要原因,它侧重于已经运行的虚拟机。资源调度也可以用于虚拟机的初始放置,使最终用户能够将工作负载组件安全地分配到适当的位置。
用于虚拟机的初始放置的资源调度基于可用区,这是一种过滤系统,使最终用户能够根据运营商定义的选项选择虚拟机放置。可用区概念也由大多数超大规模提供商使用,包括 AWS、Azure 和 GCP。
每个可用区都是一组特定的计算节点,并且最终用户可以选择是否将 VM 放置在特定区域,以进行适当的分配。例如,某些工作负载项应尽可能地彼此远离(例如,对于数据库集群)。OpenStack Nova 将虚拟机调度到适当的计算节点组,可以选择应用进一步的条件(过滤器),例如利用适当的节点或其他配置的过滤器。
对于已经运行的虚拟机,OpenStack 资源调度侧重于可能随时间变化并导致次优云利用率的计算负载,例如某些计算节点利用率不足,而其他节点负载过重,或者节点已打开但一段时间处于空闲状态。
Watcher
Watcher 是一个 OpenStack 服务,旨在优化基于 OpenStack 的云的资源。它从遥测服务收集指标,并计算一个行动计划来根据用户选择的目标优化云。行动计划包含不同的行动,例如更改计算节点的电源状态或将虚拟机从一个节点迁移到另一个节点。
Watcher 数据源
Watcher 将数据源定义为提供指标以告知集群状态的遥测服务。支持多种服务,例如 Prometheus、Gnocchi、Grafana 或 Monasca,其中前两个是最常用的。Watcher 通常会获取 VM 和主机 CPU、内存或磁盘指标,这些指标使其能够为云设计优化计划。
Watcher 操作模式
在使用 Watcher 时,云管理员可以选择手动或自动使用。在两种模式下,用户都选择要优化的目标,并且 Watcher 准备一个计划,其中包含对云的更改,以使其更接近所选目标。在手动模式下,Watcher 会生成一个计划,用户可以选择接受或不接受;如果拒绝该计划,则不会对云进行任何更改。否则,在自动模式下,将应用建议的计划。此外,在两种模式下,Watcher 都可以设置为连续优化。如果选择了该设置,Watcher 将以用户配置的定期间隔提出新的优化计划,并且用户可以选择在手动模式下接受计划或在自动模式下自动应用它们。
示例工作流程和工作策略概述
Watcher 提供了一个强大的框架,可以实现广泛的云优化目标。用户可以选择许多受支持的策略(算法实现)来帮助他们找到给定目标的解决方案。本节将介绍云管理员可能实施的一些示例工作流程
在集群中均匀分配工作负载(工作负载平衡)
将实例整合到节点上(节点资源整合)
所有工作流程都将通过管理员和 Watcher 系统之间的以下主要交互进行
所有工作流程都可以通过 CLI 或 Horizon 执行。
- 在集群中均匀分配工作负载
工作负载平衡迁移策略允许云管理员通过在服务器的 CPU 或 RAM 利用率百分比高于指定阈值时移动工作负载来平衡云负载。
管理员设置连续审核以实施工作负载平衡目标。选择的数据源将设置为监控服务器的指标。如果审核检测到任何服务器的 CPU 或 RAM 利用率超过设置的阈值,则将提供一个包含推荐状态的行动计划。行动计划包括一个迁移行动,以将负载过重的实例迁移到更均匀平衡服务器负载。管理员选择启动行动计划。一旦服务器的利用率回到阈值以下,行动计划将被标记为成功。 - 将实例整合到节点上
节点资源整合策略检查计算节点的资源使用情况。如果使用的资源少于总资源,它将尝试迁移服务器以整合计算节点的使用。
管理员使用节点资源整合策略创建审核模板,用于服务器整合的目标。然后,管理员使用创建的模板运行一次审核。如果全局效率与指定的比率不一致,将推荐一个行动计划。例如,如果全局效率显示 Released_nodes_ratio:50.00%,则表示实施此行动计划将清空 50%的计算节点。
行动列表将显示一些待处理的迁移行动。一旦管理员启动行动计划,服务器迁移将开始,并且在迁移完成后将重新启用释放的服务器。然后,管理员可以确认服务器已移动到预期的计算节点,并且所有节点都可供使用。
结论
最近对 Watcher 项目进行复兴的工作表明,它可以成为帮助管理员优化基于 OpenStack 的云基础设施资源的有效工具。展望未来,可以进一步增强 Watcher,以扩展可用的策略集,并在实施行动计划时合并相关的指标可视化。
动态资源均衡器
Mirantis OpenStack for Kubernetes 包括一个动态资源均衡器 (DRB) 服务,它简化了从 OpenStack 到 VMware 用户的过渡,这些用户在日常操作中利用自动资源调度和负载平衡。对于高级 OpenStack 用户,DRB 还通过防止 OpenStack 集群中的嘈杂邻居和热点来帮助保持最佳性能和稳定性,这可能会导致延迟或其他问题。
动态资源均衡器是一个可扩展的框架,允许云运营商始终确保其云环境中的最佳工作负载放置,而无需手动重新校准。它每 5 分钟持续收集 OpenStack 节点的资源使用指标,并自动将工作负载从超过预定义的可定制负载限制的节点重新分配。
动态资源均衡器由三个主要组件组成:收集器,用于收集服务器使用情况数据;调度器,用于做出有关工作负载放置的调度决策;以及执行器,用于将批准的工作负载迁移到适当的节点。云运营商可以根据需要限制仅针对特定可用区或计算节点组的工作负载重新分配。此外,收集器、调度器和执行器是 Python 插件,云运营商可以使用最相关的数据源和决策标准来自定义它们,以用于其工作负载和环境(例如,应用电源指标、使用不同的可观察性工具作为收集器或执行冷迁移)。
虚拟机转换
VMware 和 OpenStack 依赖于不同的虚拟化技术和磁盘格式,因此在 VMware 虚拟机可以在 OpenStack 超visor 上运行时,需要进行转换。VMware 使用 VMDK(虚拟磁盘)格式,而 OpenStack 使用 QCOW2 或 RAW 磁盘格式。
除了磁盘格式转换之外,来宾操作系统可能需要进行调整才能在 KVM 下正确启动。这包括用 virtio 兼容的驱动程序和内核模块替换 VMware 特定的驱动程序和内核模块,并适应 OpenStack 的虚拟硬件堆栈,该堆栈使用不同的网络接口、控制器和仿真模型。
要执行此迁移,有几个开源工具可用,例如 virt-v2v 和 nbdkit。
作为 libguestfs 的一部分,virt-v2v 旨在将来自 VMware ESXi 等外部超visor 的虚拟机转换为适合 KVM/QEMU 的格式。
它执行
- 磁盘格式转换(VMDK 到 QCOW2 或 RAW)
- 来宾操作系统重新配置:安装 virtio 驱动程序、更新启动设置、删除 VMware 依赖项
- 脚本注入:在转换后首次启动时运行自定义脚本以进行其他配置或清理
- Cloud-init 就绪,如果需要,允许在启动时注入 OpenStack 元数据
Virt-v2v 示例
以下是一些 virt-v2v 处理从 VMware 到 OpenStack 的虚拟机转换的示例。
1. 通过 ssh 转换为本地原始磁盘镜像的基本转换,最后可以将其上传到 Glance。在这里,需要在 ESXi / vCenter 环境中配置 ssh 访问,并且应根据您的环境设置来宾路径
virt-v2v -i vmx -it ssh "ssh://[email protected]/vmfs/volumes/datastore1/centos/centos.vmx" -o local -os /tmp/
2. Virt-v2v 也可以直接输出到 Qcow2 格式virt-v2v -i vmx -it ssh "ssh://[email protected]/vmfs/volumes/datastore1/centos/centos.vmx" -o local -os /tmp/ -of qcow2
3. Virt-v2v 直接上传到 OpenStack Glancevirt-v2v -i vmx -it ssh "ssh://[email protected]/vmfs/volumes/datastore1/centos/centos.vmx" \
-o glance -oc openstack \
-on "centos-migrated-image" \
-os "openstack"
4. Virt-v2v 与直接复制和转换为 Cinder 卷,其中 server-id 是应该运行该命令的 OpenStack 实例,并且 Cinder 卷附加到它(需要以 root 用户身份运行)virt-v2v -ip passwd \所有详细选项可以在这里找到:https://libguestfs.org/virt-v2v-input-vmware.1.html
-ic 'esx://[email protected]/Datacenter/192.168.122.1?no_verify=1' \
-it vddk \
-io vddk-libdir=/usr/lib/vmware-vix-disklib \
-io vddk-thumbprint=XX:XX \
-o openstack -oo server-id=459b2b84-fcde-4ad9-9db2-2aa8c4c61445 \
centos
Nbdkit 示例
以下是一些使用 nbdkit 将 VMware 来宾转换为 OpenStack 的基本示例
Nbdkit 与 vddk 插件允许您直接从 VMware 环境获取来宾磁盘,从磁盘、已关闭的虚拟机或带有快照的实时虚拟机。
nbdkit --readonly vddk <br> libdir=/usr/lib/vmware-vix-disklib <br> server=vcenter <br> user=Administrator@vcenter <br> password=your_password <br> thumbPrint=XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX <br> vm=moref=vm-9 <br> snapshot=snapshot-1 <br> compression=skipz <br> transports=file:nbdssl:nbd <br> [datastore1] centos/centos.vmdk 然后可以使用 nbdcopy 将网络块设备消耗到本地磁盘
nbdcopy nbd:// /tmp/local.disk --progress 重要提示:您也可以直接写入附加到 OpenStack 实例的 Cinder 卷。
最后,使用 virt-v2v 转换磁盘
virt-v2v-in-place -i disk /tmp/local.disk 重要提示:在此阶段,您可以受益于 virt-v2v 的所有选项,特别是 –firstboot、–firstboot-command、–firstbootand-install 和 –run 选项,以自定义磁盘在转换期间或虚拟机的首次启动期间。
Ansible 和自动化
如果需要虚拟机转换并且您将使用自动化(可能是一个 Ansible 脚本)而不是手动执行,那么您需要掌握一些信息来帮助该过程。例如,您可能需要收集有关 Guest 和 VMware 环境的信息,例如虚拟机路径,以及诸如 moref ID 或快照 ID 之类的特定值。
为此,有 Govmomi Golang 包,还有用于 VMware 的 Ansible 集合,它们为运行虚拟机迁移和转换提供有价值的信息。
OS-Migrate 和 vJailbreak 使用这些库来自动化和运行整个从 VMware 到 OpenStack 的迁移和转换过程,具有非常好的性能和可扩展性。
Windows 驱动程序
对于 Windows 虚拟机,virtio-win 包提供了转换所需的所有驱动程序。请确保您的系统上具有最新的软件包版本,以便转换最新的 Windows 版本。
硬件建议
一般注意事项
可以使用各种硬件进行云计算,但以下原则指导着良好的硬件选择
- 故障域设计:应部署云服务器,以便物理故障域与逻辑故障域(例如,可用区)匹配。这同样适用于软件定义存储。OpenStack 控制平面也应部署在至少三个故障域中,以确保服务器发生故障时仍能继续运行。
- 中端:云服务器在 CPU、内存和存储配置方面应处于入门级和高端之间。
- 入门级服务器使得放置更大的工作负载变得困难,并且可能导致浪费资源。
- 高端服务器容易出现网络和存储瓶颈,因为许多工作负载争夺 I/O。如果服务器发生故障,它们还会增加爆炸半径,因为大量工作负载会受到影响。
- 减少复杂性:除非有充分的理由,否则应避免使云配置、维护或生命周期管理复杂化的解决方案。示例包括
- 过多的云段(可用区和主机聚合)使得放置工作负载变得复杂,有时甚至不可能,即使仍有可用容量。
- 计算节点理想情况下应采用相同类型,以便在发生故障时易于更换,并避免由于硬件类型不同而出现多个主机聚合。
重用现有硬件
在迁移场景中,通常首先建立 OpenStack 目标集群控制平面,以及一些计算和存储节点。随着迁移的进行,源环境中的节点被释放,并且通常在目标环境中重新部署。
许多 VMware 环境由适合 OpenStack 使用的节点组成。最合理的是,最近的 x86_64 硬件都可以使用,尽管在某些情况下,可能需要内存增强、存储或其他资源。
硬件配置的一般建议
- 闪存存储:特别推荐使用闪存存储用于控制平面,也推荐用于镜像和通用块存储。由于在压力下具有更广泛的性能范围,NVMe 是首选,但也可以考虑 SATA SSD。只有对于存档存储类型(备份)才应使用硬盘,因为它们在重度并行访问下表现不佳,而这在大多数云中都很普遍。许多 VMware 环境已经全部使用闪存,但如果将要迁移的环境未使用闪存,那么现在是更换磁存储为闪存的好时机。
- 内存配置:由于许多用户共享相同的硬件,内存性能比在大多数专用节点上影响通用性能更大。特别是,CPU 的所有内存通道都应填充。CPU 规格表中的内存通道数必须乘以 CPU 的数量,以确定应使用的最小内存模块数量。应根据大小调整容量,而不是内存模块的数量。现有的服务器通常可以轻松修改以遵循此建议。
- 网络和存储 I/O:具有更强大 CPU 的计算节点会将更多工作负载集中在每个节点上,这将争夺网络和存储 I/O。可以通过增加服务器中的网络端口(额外的网卡)或迁移到更快的网络基础设施(例如,100GbE)来缓解瓶颈。由于 OpenStack 安装通常使用绑定以实现性能和弹性,因此应始终成对或更高倍数添加网卡端口。
减少与现代化
是否应重用/集成旧组件的问题归结为三个因素
- 经济性:从功耗、冷却要求和密度与硬件提供的性能相关的角度来看,硬件是否仍然经济可行?
- 可靠性:硬件是否接近其使用寿命的结束,这将使更换更加频繁和更具挑战性?
- 密度:随着对计算、GPU 和存储的需求迅速增加,升级现有硬件是否比部署额外的机架甚至数据中心更便宜?
- CPU 性能和线程数激增。这允许在云环境中实现更高的密度,从而降低成本、功耗和冷却成本。由于芯片组将它们连接到主板的 CPU 代数特定,因此无法跨代升级 CPU。
- 可以通过添加模块来增加内存,但旧一代服务器的内存速度较慢,并且 CPU 的内存通道比当前服务器少。
- 存储也变得更快且更便宜。此时,硬盘对于任何其他纯存档/备份存储而言都是过时的。服务器通常可以升级为 SATA/SAS SSD
- 可以通过更换网络接口卡来升级网络适配器。
整合
许多 VMware 客户在生产环境中拥有各种小型环境,这些环境通常随着时间的推移而增长,而不是一次性设计。迁移到云环境为合并和正确设计目标环境提供了机会。设计阶段应包括对硬件的彻底评估。
2024 年,OpenInfra Foundation 和 OpenStack VMware 迁移工作组与行业记者 Steven J. Vaughan-Nichols 合作开发了 VMware 迁移白皮书。该出版物解决了 Broadcom 收购 VMware 的影响,并鼓励组织在迁移时调查 OpenStack 作为一种选择。
案例研究与参考架构
Canonical
参考架构
Canonical OpenStack 参考架构 利用现代、云原生设计,控制平面由 Canonical Kubernetes 编排,并且 Sunbeam 极大地简化了部署。这种方法提供了一个高度自动化、可扩展且具有弹性的私有云,适用于各种企业和云服务提供商的工作负载。
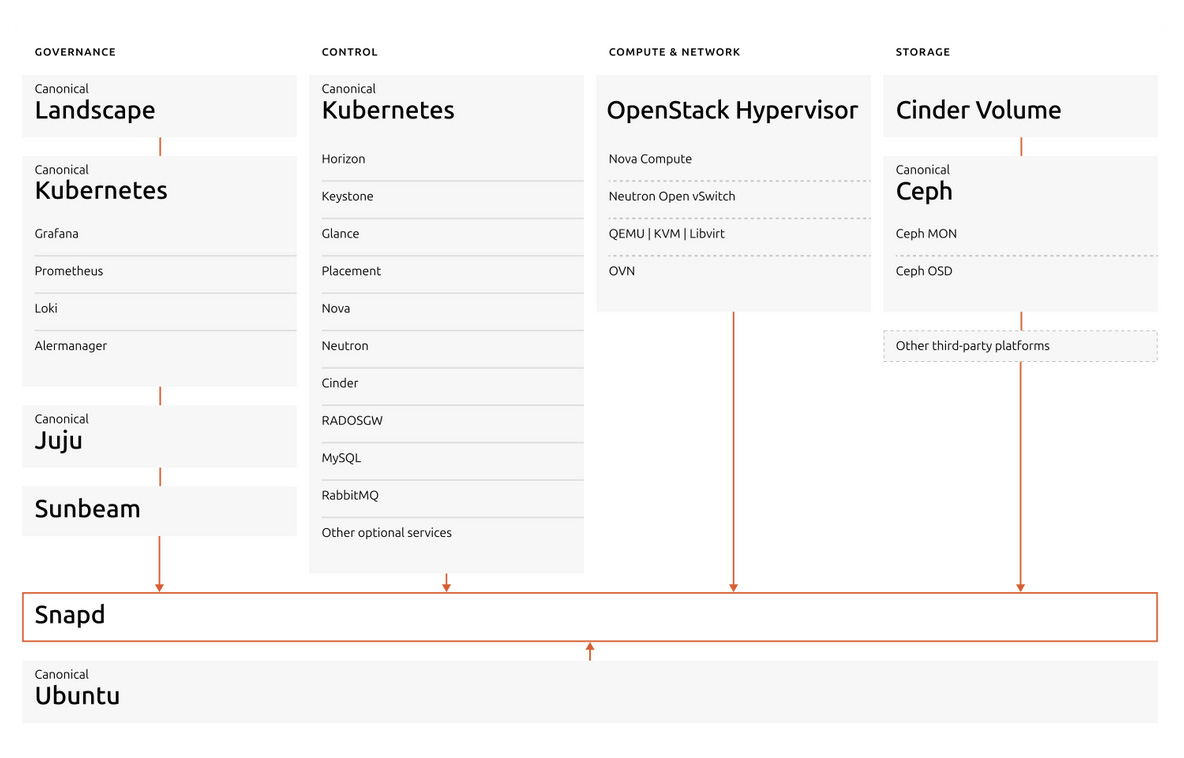
- 控制平面 - Canonical Kubernetes 托管:OpenStack 控制平面被容器化并由 Canonical Kubernetes(Charmed Kubernetes 或 MicroK8s)编排,提供强大的自动化、可扩展性和生命周期管理。所有主要的 OpenStack 控制服务——例如 Keystone(身份)、Nova(计算调度)、Neutron(网络)、Glance(镜像服务)和 Horizon(仪表板)——都作为 Kubernetes 托管的工作负载运行。这种架构能够实现无缝升级、高可用性和快速扩展,同时利用 Kubernetes 原生功能实现弹性及运营的简易性。使用 Kubernetes 作为基础可确保 OpenStack 的 API 和 RPC 服务、数据库和消息传递层作为微服务高效管理,Charmed Operators(charms)处理部署、扩展和健康检查。
- Sunbeam - 简化的部署和操作:Sunbeam 是 Canonical 的上游 OpenStack 项目,旨在降低进入门槛并简化部署和持续操作。Sunbeam 使用完全自动化和高级抽象,即使是非专家也能在几分钟内启动生产级别的 OpenStack 云。它利用 Kubernetes 进行容器编排和 Juju 进行基于 charm 的自动化,允许用户像任何其他云原生应用程序一样部署、配置和扩展 OpenStack 服务。Sunbeam 支持从小规模到大规模的部署,使 OpenStack 适用于从单节点边缘云到大型数据中心数千个超融合服务器的一切。
- 计算节点:计算节点运行 Nova 计算服务和虚拟化堆栈(KVM、Libvirt/QEMU),将用户工作负载作为虚拟机托管。这些节点可以水平扩展,并且也可以在超融合设置中运行存储服务。软件定义网络 (SDN) 组件,例如 OVN 或 OVS,以及 Neutron 代理,也部署在计算节点上,以提供高级网络功能和实例元数据服务。
- 存储:该架构支持块存储 (Cinder) 和对象存储 (Swift 或 Ceph)。存储可以部署在专用节点上或在超融合模型中与计算一起部署,从而实现灵活的扩展和高效的资源利用率。Ceph 通常用于统一的块和对象存储,提供高性能、耐用性和可扩展性。
- 网络:Neutron 提供高级 SDN 功能,与 OVN 或 OVS 集成,以实现自动化的网络配置、分段和安全性。网关节点管理外部连接、NAT 和浮动 IP,而安全组和防火墙提供租户级别的网络隔离和保护。
- 自动化和生命周期管理:MAAS(Metal as a Service)自动化硬件配置,将裸机转换为云就绪的基础设施。Juju,Canonical 的模型驱动的运算符框架,编排 OpenStack 服务的部署、扩展和生命周期管理,实现基础设施即代码和快速运营变更。
- 监控和管理:集成的监控工具和仪表板(例如 Horizon 和 Landscape)提供对云运行状况、性能和安全性的实时可见性。这支持通过自动补丁、集中监控、合规性和高效运营来实现主动维护。
Canonical 的参考架构,由 Kubernetes 托管的控制平面和 Sunbeam 的自动化提供支持,可提供面向未来的高度自动化的 OpenStack 云。它降低了复杂性、加速了部署,并确保了无缝的扩展和升级,使 OpenStack 适用于任何规模的组织。
有关完整技术详细信息、架构图、详细参考硬件和软件架构,请参阅 Canonical OpenStack 参考架构指南。
案例研究
Canonical 帮助各种工作负载从 VMware 迁移到他们的 Canonical Openstack。迁移的工作负载范围从电信到金融服务再到研究和公共服务!在此 Superuser 帖子中查看列表和详细信息。
华为
参考架构
华为电信云平台构建了一个基于 OpenStack 和 Kubernetes 的融合双引擎架构。与 OIF 和 CNCF 社区合作,华为电信云平台以 OpenStack 作为虚拟化层上的核心云操作系统,并增强了电信场景下的功能,同时贡献开源项目。与社区和电信生态系统合作伙伴合作,我们共同提高 OpenStack 和 Kubernetes 云平台的性能、可靠性和开放性,以满足运营商级服务的严格要求。
在性能方面,该平台通过软硬件协作实现端到端定制和优化,以实现最佳性能。华为在硬件层开发了专用设备,例如转发加速卡、网络卸载卡和网格卡,以满足运营商级服务的定制要求。软件层基于开源框架进行深度增强,并支持关键功能,例如动态巨页内存、核心固定、NUMA 亲和性调度、VF 直通等,这些功能有效地提高了整体计算和网络性能。
在可靠性方面,该平台简化了硬件、虚拟化、网络和应用程序层之间的协作调度机制,以构建端到端高可靠性架构,并实现运营商级 99.999% 的可用性。此外,该系统支持 VM HA 和容器 HA,并提供极端生存能力,例如存储旁路,确保关键任务服务在极端场景下的连续性。
在开放性方面,该平台架构符合 ETSI 标准。它具有良好的兼容性和持续演进能力,并有效地降低了与外围系统的互连成本。该平台完全支持本机开源功能。第三方应用程序可以在北向部署,异构硬件可以在南向兼容,从而为运营商提供更大的灵活性,并帮助运营商快速扩展多样化的服务。
在性能方面,该平台通过软硬件协作实现端到端定制和优化,以实现最佳性能。华为在硬件层开发了专用设备,例如转发加速卡、网络卸载卡和网格卡,以满足运营商级服务的定制要求。软件层基于开源框架进行深度增强,并支持关键功能,例如动态巨页内存、核心固定、NUMA 亲和性调度、VF 直通等,这些功能有效地提高了整体计算和网络性能。
在可靠性方面,该平台简化了硬件、虚拟化、网络和应用程序层之间的协作调度机制,以构建端到端高可靠性架构,并实现运营商级 99.999% 的可用性。此外,该系统支持 VM HA 和容器 HA,并提供极端生存能力,例如存储旁路,确保关键任务服务在极端场景下的连续性。
在交付层面,引入了自动工具链,可以自动输出关键设计文档,例如 HLD、LLD、NSD 和 VNFD,从而将人工成本降低 90%。在交付阶段,该平台支持预集成能力,提高了交付效率 50%。此外,支持一键 VNF 部署和自动 ATP 测试用例,大大减少了交付过程中的手动工作量,并将运营负载减少了约 90%。
在 O&M 层,平台提供统一的跨层可视化 O&M 门户,用于定位和划分从硬件到应用程序的所有链路上的故障,将故障定位效率从几天或几周缩短到几分钟或几天。
案例研究
华为电信智能融合云 (TICC) 解决方案在电信云建设方面展现出显著优势。该解决方案支持从规划、部署到测试的全端自动化,大大缩短了项目推广周期 (TTM)。要了解 TICC 如何支持沃达丰继续走在电信网络云化的前沿,请查看此案例研究!
Okestro
参考架构
Contrabass 迁移服务 (CMS) 是一种高度自动化的原地迁移 (rehosting) 解决方案,允许您在不丢失数据或长时间切换窗口的情况下,将大量虚拟机从 VMware vSphere 迁移到 Okestro Contrabass,并使用基于 Web 的控制台进行集中管理。目前,CMS 支持 VMware vSphere 虚拟机的迁移,但在不久的将来,它还将支持从物理服务器、虚拟机和各种超融合服务器的迁移。
CMS 通过拍摄快照定期复制源服务器到 Contrabass,并使用 CMS 专有的复制引擎持续复制数据,从而提供仅几秒钟的切换窗口。该复制引擎提供实时、异步、文件记录级别的复制,用于实时迁移,并在操作系统级别运行。即使没有复制引擎,CMS 也能确保最小的停机时间(几分钟)和迁移过程中的零数据丢失。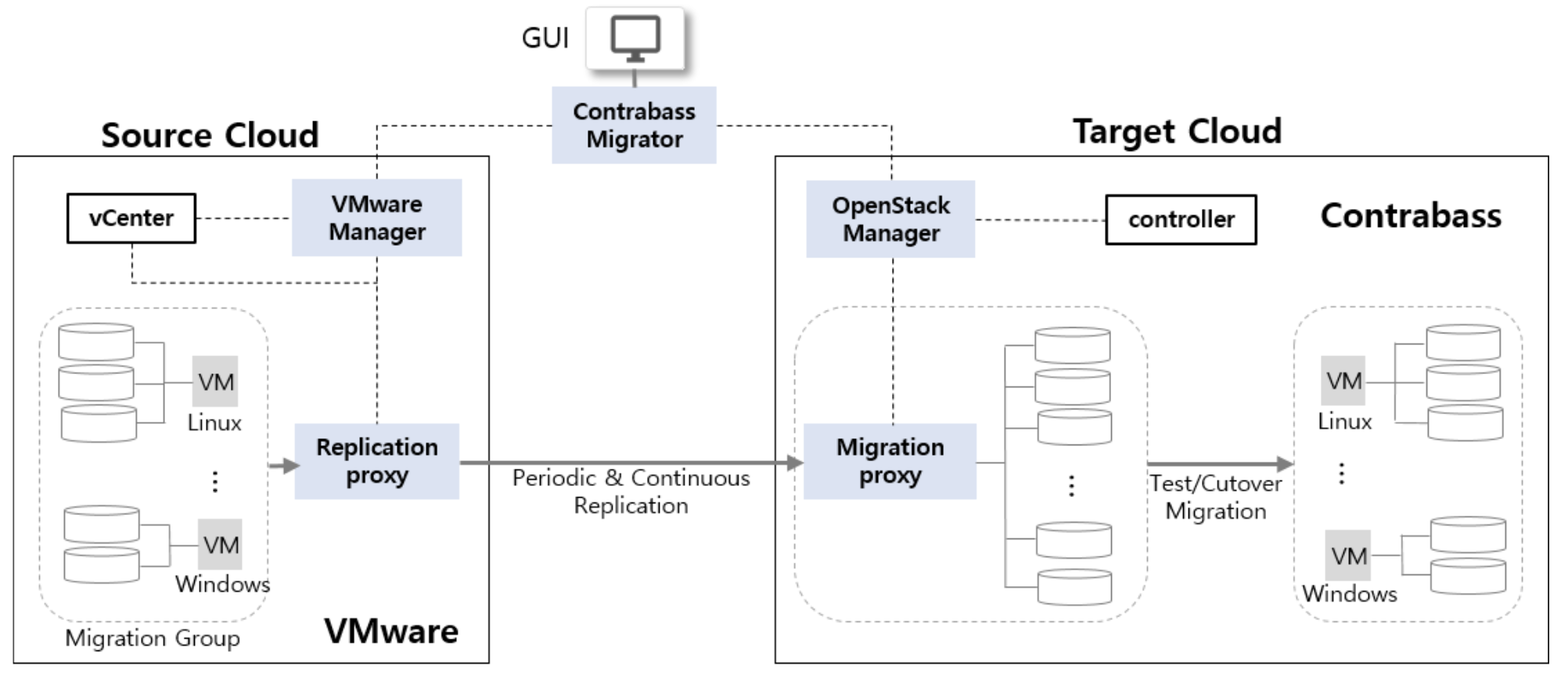
CMS 由五个主要组件组成:Contrabass Migrator、VMware Manager、OpenStack Manager、Replication Proxy 和 Migration Proxy。可选地,复制引擎可以安装在每个源服务器上,以实现仅几秒钟的切换窗口。
- Contrabass Migrator 作为 CMS 的大脑,协调和管理整个迁移过程,包括规划和执行。
- VMware Manager 发现并管理要迁移的源服务器的所有相关信息,例如网络、IP 地址和安全组。
- OpenStack Manager 发现并管理目标集群中的资源,包括用于托管迁移服务器的节点以及与源环境对应的网络。可以通过基于 Web 的 CMS 控制台配置这些资源。
- OpenStack Manager 还处理启动 Okestro 上实例所需的资源的完整配置,例如网络接口和防火墙。
- Replication Proxy 定期或持续地将源服务器复制到 Migration Proxy。初始复制可能需要几个小时到几天,具体取决于数据量以及源集群和目标集群之间的可用带宽。CMS 允许用户定义特定的复制窗口,以避免影响源系统性能。
- Migration Proxy 协调复制任务,转换服务器镜像,并调整应用程序堆栈,使迁移的服务器能够在目标集群上平稳运行。
案例研究
要了解有关 Contrabass Migrator 工具以及 Okestro 如何利用它来支持韩国一家国有公司,请查看 Superuser 案例研究!
Mirantis
工作负载迁移架构
Mirantis 工作负载迁移服务包含多个组件,可自动执行从 VMware 到 MOSK (OpenStack) 的迁移过程,采用典型的原地迁移方法。工作负载是最重要的实体,因此该工具提供减少切换期间可用性影响的功能。虚拟机数据在后台复制到目标环境,不会中断源侧上运行的工作负载。
初始复制后,所有机器将在目标侧启动,以验证工作负载的功能。成功验证后,可以规划最终切换,这意味着源机器的短暂停止和增量数据的传输。可以长时间持续复制增量数据。这允许在源仍在运行的同时,在目标侧执行更复杂的测试。
可以并行执行迁移,以提高吞吐量和整体迁移过程的速度。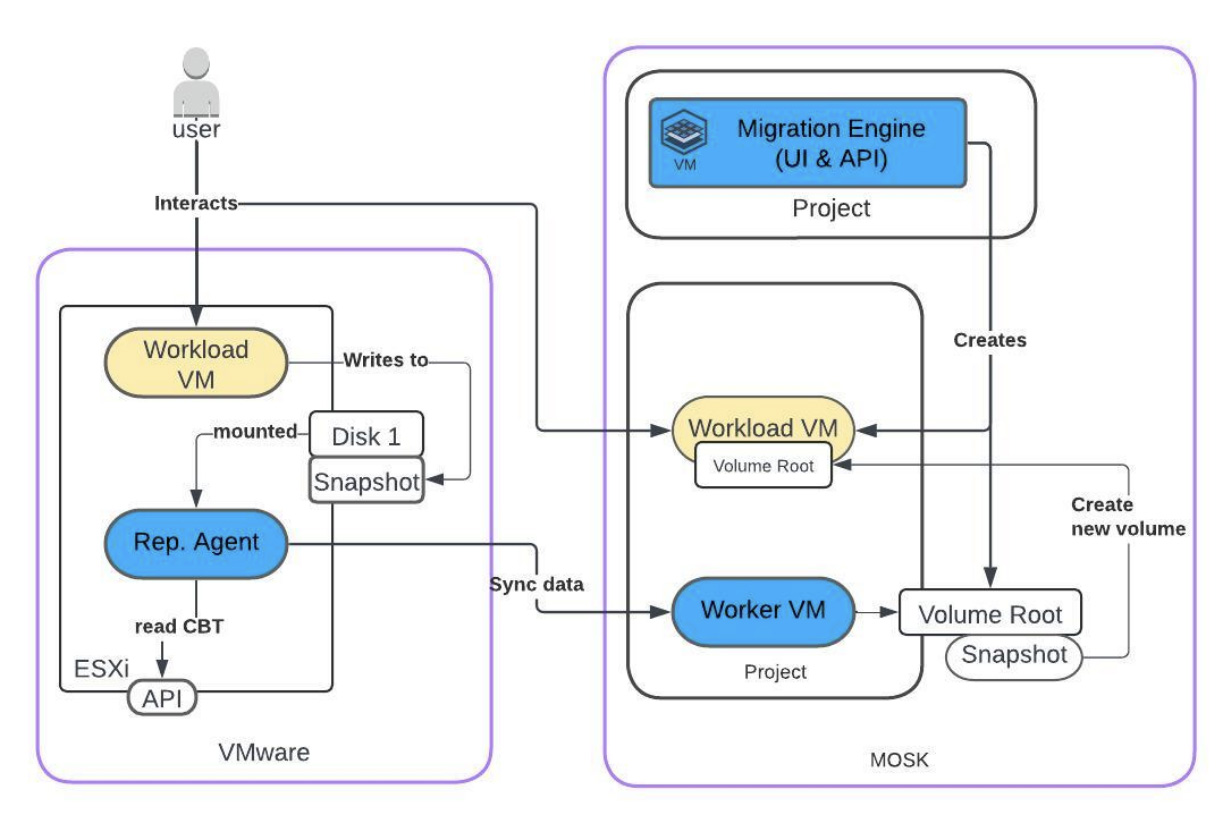
迁移引擎 - 部署在目标侧,并管理整个迁移过程。它提供用户友好的界面,还提供 API 以扩展自动化或集成到现有的自动化模式中。
复制代理 - 通常作为虚拟机在每个 ESXi 主机上运行,扫描主机上的所有可用机器及其常规信息。Rep. Agent 负责在源上创建快照(启用 CBT)并初始化到目标工作机器的数据传输。
工作虚拟机 - 在迁移完成直到最终切换之前,会在每个目标项目上临时生成。工作机器负责附加新创建的卷(持久存储)作为源磁盘的目标。
案例研究
凭借 Mirantis k0rdent AI,Nebul 作为荷兰领先的欧洲私人和主权 AI 云提供商,也拥有实现更广泛市场所需的运营效率和可扩展性。该云服务提供商旨在扩展到欧洲各地的数据中心,帮助更多客户安全地加入 AI 革命,同时保护其公司数据并确保符合不断增长的数据隐私、安全和主权法规。要了解更多关于此用户案例研究的信息,请查看完整的博客文章。
风河
参考架构

Wind River 已经提供了基于 OpenStack 的解决方案多年,并已将其架构发展到在单个统一技术堆栈内无缝集成 Kubernetes。该现代平台由 StarlingX 提供支持,StarlingX 是一个领先的开源项目,专为边缘和云原生部署而构建。凭借集成的平台、自动化的编排和内置的分析功能,组织可以自信地优化其私有云环境,同时为边缘、近边缘、核心和 IT 环境提供低延迟性能。无论从传统的 VM 工作负载迁移,还是增强现有的私有云运营,Wind River Cloud Platform 都能提供企业所需的可靠性、灵活性和成本效益。
将 VM 和容器从 VMware vSphere 迁移到 Wind River® Cloud Platform 利用 OpenStack 和 Kubernetes 在单个集成环境中托管两种工作负载类型。这个开放、灵活且具有成本效益的平台为组织提供了部署和管理全球私有云基础设施所需的工具,支持地理分布式网络中的运营技术 (OT) 和信息技术 (IT) 工作负载。
案例研究
Wind River 一直在帮助组织无缝迁移虚拟机 (VM) 和容器工作负载从 VMware,利用其独特的自动化能力——即使是在世界上一些最复杂和最具挑战性的云网络中。有兴趣了解更多关于他们的 VMware 替代方案吗?请查看 Superuser 上的文章!
中兴通讯
总体迁移流程:“四步闭环”确保平稳过渡
以一家国有企业的测试实践为例,ZTE TECS 迁移工具通过四个主要阶段构建安全可控的端到端迁移闭环:完全复制、增量同步、验证测试和服务切换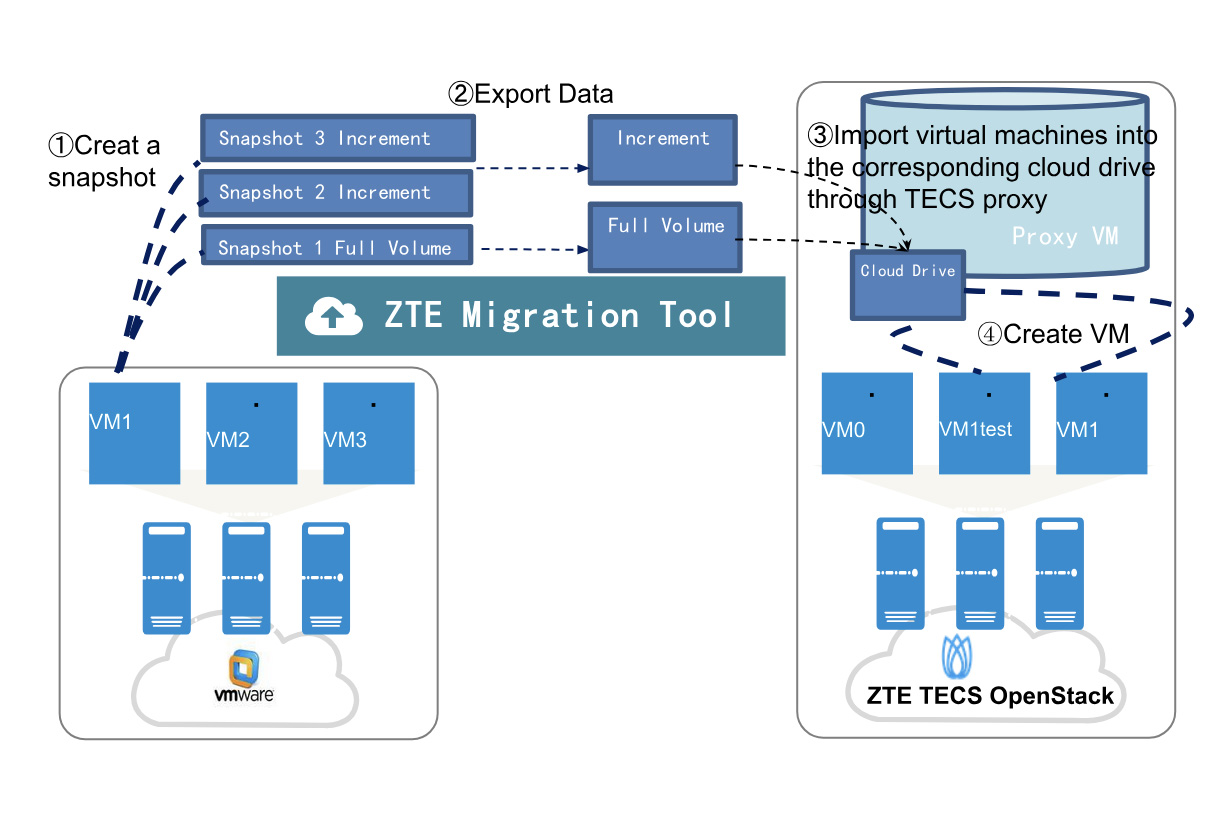
阶段 1:完全数据复制
该工具自动调用 VMware API 以生成源 VM 快照,并将完整的数据镜像复制到目标 TECS 集群,而不会影响源操作,从而确保初始数据一致性。
阶段 2:增量数据同步
完全复制后,启动定期增量同步。差异快照捕获源数据更新,动态地将目标集群与实时源数据对齐,以最大限度地减少切换停机时间。
阶段 3:验证测试
同步后,在隔离的环境中部署克隆的测试 VM 以模拟服务场景。在网络隔离下,运维团队验证数据完整性和服务可用性,以减轻切换后异常情况。
阶段 4:最终服务切换
分钟级停机时间:关闭源 VM 后,执行最终增量同步,目标自动完成 VM 创建、网络配置和驱动程序适配。
无缝接管:服务验证后,重定向流量,将总停机时间压缩到几分钟,确保关键业务连续性。
技术亮点:平衡安全性和效率
无代理模式保障数据安全
零入侵设计:消除了传统的基于代理的方法,需要 VM 插件,直接利用 VMware vCenter API 进行快照,以防止数据篡改,满足严格的金融行业完整性标准。
资源效率:避免了代理引起的 VM 资源消耗,提高了迁移性能。
API 驱动的端到端控制
灵活的调度:支持自定义迁移时间、增量周期和切换窗口(例如,非高峰/周末),并具有检查点恢复功能,以最大限度地减少对业务的影响。
快速回滚:在验证失败时一键恢复到源,最大限度地减少中断并确保风险可控的迁移。
客户价值:增强无缝性和自主性
无缝、未察觉的迁移
API 驱动的调度确保完整的迁移在目标准备就绪后的非高峰时段完成,而增量同步和切换则集中在低流量时段,从而提供零干扰的用户体验。
核心技术自主性
硬件层:支持从 Intel 切换到国产海光平台。
虚拟化层:TECS 平台实现全栈国产化,降低外部依赖,符合国家创新战略要求。
提供服务的 OpenStack 生态系统公司的非详尽列表
- Atlancis
- AWcloud
- Canonical
- China Telecom
- Cloud & Heat
- Cloudbase Solutions
- 云化
- Coredge
- Debian
- EasyStack
- 爱立信
- Fujitsu
- H3C
- 华为
- Inspur IEIT Systems
- Mirantis
- Okestro
- OSISM
- Red Hat
- Sardina Systems
- Taikun OCP
- Ultimum Technologies
- Whitestack
- 风河
- ZConverter
- 中兴通讯
- Ceph
- Dell Technologies
- NetApp
- Pure Storage
- Red Hat
- Scality
- Storware
- Taikun CloudWorks
- Atlancis
- Canonical
- 中国移动
- China Telecom
- China Unicom
- Cleura
- Cloudbase Solutions
- Cloud&Heat
- 云化
- DevStack
- Deutsche Telekom
- EasyStack
- Elastx
- Fairbanks
- 华为
- Infomaniak
- Inspur IEIT Systems
- Mirantis
- Netways
- Okestro
- OpenMetal
- OVHcloud
- Planethoster
- Platform9
- Rackspace
- Red Hat
- Safespring
- Sardina Systems
- Sharktech
- Taikun OCP
- Ultimum Technologies
- Vexxhost
- ZConverter
- Canonical
- OpenMetal
- Sardina Systems
- Sharktech
- Spot by NetApp
- Vexxhost
- ZConverter
- Canonical
- Datadog
- Grafana Labs
- Hydrolix
- Mirantis
- Red Hat
- 备份和恢复
- Cloudbase Solutions
- Commvault
- Hystax
- NetApp
- Storware
- Trilio
- Veeam
- Zadara
- B1 Systems GmbH
- Canonical
- Cleura
- Cloudbase Solutions
- 云化
- Coredge
- Fairbanks
- 华为
- Mirantis
- Okestro
- OpenMetal
- OSISM
- Red Hat
- Sardina Systems
- SUSE
- Vexxhost
- ZConverter
作者
Marios Andreou, Mathieu Bultel, Ken Crandall, Ralph Dehner, Jennifer Fowler, Christian Huebner, Damian Karlson, Heiko Krämer, Natallia Kulazhenka, Ronelle Landy, Paweł Mączka, Jimmy McArthur, Joan Francesc Gilabert Navarro, Kendall Nelson, Dan van der Ster, Michelle Yakura, Christian Wolter