简介
在计算的历史中,一个持续的主题是抽象层的叠加。将关键技术封装在新接口中,可以使计算更易于使用、更可靠、更安全。直接硬件编程反过来使用 API 通过接口使用低级系统库和通用驱动程序抽象。在应用程序编程层,API 用于构建应用程序,这些应用程序通过 Web 或 RESTful API 进行联网。应用程序托管在虚拟化服务器中。通过在裸机超visor上引入容器,虚拟化变得更轻量级且更易于扩展。应用容器本身也随着函数即服务或无服务器计算的兴起而被抽象化。
然而,所有这些软件抽象层之下,还有一个基本要素:需要正确配置和管理的硬件来托管应用程序。这是计算中的一个普遍问题,无论您使用的是像手表或手机这样小的设备,运行个人电脑,还是托管一个提供数百万请求的服务器集群,每个应用程序都直接或间接地从物理硬件的精简配置开始,即现成的裸机。尽管计算抽象取得了所有进展,但裸机管理仍然是一个必须解决的基本问题。这类似于建筑领域,无论您使用什么框架或建筑材料,地基都必须坚固、稳定和安全,以承受负荷、压力和应力,以及地震、洪水、闪电甚至疫情等自然灾害。
虽然是一个基本或基础的主机问题,但我们仍然可以将抽象和自动化的工具应用于解决它,使整个数据中心或任何远程站点的配置就像在终端中键入单个命令或在网页表单上按下“提交”一样简单。
在本文中,我们将探讨开源社区如何使用完全免费的开源软件解决裸机配置问题。我们将讨论运营商或企业在发现和配置服务器时面临的问题,OpenStack 社区如何通过 Ironic 项目解决这些问题,Ironic 在生产环境中的具体案例研究,以及开源基础设施和硬件管理的未来。
动机
缺乏裸机 API 的标准化导致第一天配置主机系统存储和网络的大量系统安装程序。随后对第二天管理活动(例如固件更新和升级)的处理是临时性的,导致停机时间延长,从而降低了平台对业务和关键用途的可用性。此外,使用非标准硬件或 API 进行远程自动化会导致并行部署效率降低。
其他方面是劳动力成本以及数据中心员工在数据中心内工作所面临的痛点。由于非标准硬件和缺乏标准工具和解决方案,在不方便的时间在现场解决问题或远程管理需要更长的时间。
几年前,在一个会议上,我坐在一位我不认识的人旁边。他开始告诉我他的工作和他在数据中心的长工作时间。他问我做什么,我告诉他我在开源软件方面工作。然后他开始谈论他最近发现的一种工具,可以将通常需要近两周才能完成的服务器机架任务缩短到几个小时。他因为找到了名为 Ironic 的裸机即服务工具而感到非常高兴,因为他的生活质量和工作幸福感得到了极大的提升。
作为贡献者,这就是我们贡献的原因。为了让那些生活变得更好。 - Julia Kreger,Ironic PTL
社区如何凝聚
在 OpenStack 社区中,早期存在将 Compute 抽象扩展到物理机器的愿望。社区希望提供一种通用的模式和访问方法,以便请求最终的“Compute”资源,这些资源由整个物理机器组成,而不是通常作为虚拟机提供的物理机器的一部分。这最初是“nova-baremetal”组件。
随着时间的推移,以及安全地提供物理资源所需的模式与提供虚拟机不同,缺点开始显现。许多在虚拟机生命周期期间的标准操作对于物理机器来说不那么有价值或可行,例如实时迁移或搁置。最终,在虚拟机的情况下,您只需在完成操作后删除虚拟机实例即可。对于物理机器,必须在将物理机器提供给新用户之前将其清理并重新配置为已知的基本状态。
这些所需的工作流程以及由此产生的用法冲突最终促成了“Ironic”项目的创建,作为中立的供应商空间,这些常见的工作流程可以在代码中存在,以及支持各个供应商的硬件和集成的特定模式。
实地调研
自动化、无人值守的机器设置问题并非新问题。许多项目和公司都曾尝试过这个看似困难的问题。似乎复杂性在于涉及机器配置的许多活动部分。除此之外,所需的机器配置可能因机器而异。
典型的机器配置可能包括
- 从可用服务器池中选择最合适的服务器
- 应用特定于硬件(如网络接口或 RAID 控制器)和低级软件(如固件或 BIOS)的配置
- 加载适当的软件(操作系统、驱动程序、应用程序)以及用户数据
- 应用必要的更新以最大程度地减少软件中的漏洞
- 配置网络堆栈、监控、应用程序等。
也许受手头任务的指导和底层技术的限制,机器配置项目具有一些相似之处。它们通常依赖于用于主板或系统卡的硬件管理通用标准,使用带外 (OOB) 接口,如 IPMI1 或 Redfish2。它们使用 PXE 套件进行网络启动,配置管理软件(Ansible、Puppet 等)进行机器定制,以及较新的实现提供 REST API 作为集成点。
要列出一些知名开源配置项目,Cobbler3 和 Foreman4 最初专注于自动化 Red Hat Enterprise Linux 机器生命周期管理。较新的实现,如 Canonical 的 MaaS5 和 Ironic,旨在与云软件一起工作,以与云实例相同的方式向运营商表示裸机。
在本文中,我们将重点介绍 Ironic 项目如何支持 Open Infrastructure 运营商社区的用例,涵盖被认为必要的流程和集成。请注意,这是一项新的举措,旨在将集成的计算服务 Nova 和 Ironic 与集成的 OpenStack 分开。
为什么选择裸机?
当我们回顾导致 Ironic 项目创建的最初愿望时,它支持裸机即服务 (BMaaS),或最终在不同的物理机器上提供“Compute”资源。
人们经常想知道,“为什么不能使用 VM?”或“为什么需要整个物理服务器?”原因各不相同,但往往是几个不同的基本原因之一。
性能
虽然提供了一个额外的抽象层,旨在增加灵活性和提高整体效率,但虚拟化资源会降低应用程序可用的整体性能。可以通过各种技术来减少虚拟化税,例如固定核心、利用 NUMA 结构或启用大页面,但虚拟机永远无法向托管的应用程序提供底层硬件的全部资源。此外,降低推断的额外延迟和抖动可能会带来显著的额外复杂性——因此成本——必须平衡与虚拟化环境的优势。这显然是一个普遍问题,但在高性能计算 (HPC) 环境中,充分利用购买的硬件至关重要,因此虚拟化通常不是一个现实的选择。
除了普遍的性能损失外,由“嘈杂的邻居”引起的性能随时间的变化也可能对托管的应用程序造成问题。例如,如果底层系统的抖动大于优化收益,则调试应用程序的性能是不可行的。
安全
对共享通用平台的担忧是使用不同物理机器的有力动力。无论应用程序或租户的工作负载是在容器内还是虚拟机内运行,都可能存在逃逸攻击。这可能是为了搜索数据或进行枢轴并攻击其他系统。这些漏洞可能不仅是底层平台或操作系统代码,甚至可能是物理机器的处理器中的某些内容,例如最近的 Spectre/Meltdown 侧信道攻击6。类似的论点适用于网络和存储。直接使用(从而管理)物理资源可能是可取的,当软件定义解决方案的虚拟分离被认为不足时。
合规性和堆栈独立性
服务合同或行业/政府法规可能出于多种原因需要完全不同的物理系统
- 为了支持出于安全考虑的不同角色
- 为了确保托管应用程序的基线性能
- 为了进行适当的成本/性能建模
- 由于许可限制
一个相关的合规性示例是需要与任何共享基础设施完全独立的关键设备,例如底层超visor。这确保了在发生事件时,托管服务不会被其他服务的性能或所需操作阻止或影响。
不可虚拟化的资源
最终,基础设施的某些组件不能(或不应)被虚拟化。这包括引导基础设施的节点,以及基础设施堆栈的最低层,通常是超visor 本身。
对于其他基础设施服务,如存储或数据库,虚拟化也没有太大意义:需要整个节点的虚拟机,并且额外的虚拟化层的收益可能不如上述虚拟化税或水平服务拆分的额外复杂性。
生命周期管理
虽然可能更喜欢裸机节点而不是虚拟化资源,但物理节点的主要缺点是管理其生命周期的复杂性。从安装物理服务器的那一刻到将其移除的那一刻,服务器通常会经历几个阶段。必须执行的标准操作包括
- 自动发现和注册(与库存系统或网络数据库)
- 健康检查和老化(组件完整性和压力测试)
- 基准测试(例如作为验收的一部分)
- 硬件配置(例如 RAID 设置或 BIOS 设置)
- 使用对象存储或键值存储代替 RAID 以实现本地或全局可靠且具有弹性的持久性
- 配置到最终用户或服务
- 硬件健康监控
- 维修和组件更换(包括更新库存数据库)
- BIOS 和/或 UEFI 固件更新
- 退休(例如安全数据擦除)并从上述数据库中删除
每个步骤都有其自身的困难和挑战,让我们以配置到最终用户/服务为例,进行更深入的了解。
分层数据中心操作中的一个常见要素是在团队之间以有效的方式分配服务器,例如当服务器准备好投入生产并可以移交给最终用户/服务时。必须定义接口来提交资源请求,遵循审批流程,执行实际的服务器移交,包括其凭据,或准确地计算使用的资源。此外,资源需求会随时间波动,导致“专用”物理节点的性能利用率低下或工作负载因物理节点数量有限而延迟/影响业务成果。资源在不同用户之间的重新分配成为额外的要求,并随之而来的是用户之间安全数据擦除的需要,网络配置的重置或集成系统中(如基板管理控制器 (BMC))的凭据重置。这些任务和工作流程的复杂性因环境而异,但自动化和接口支持对于以高效且可扩展的方式完成此操作至关重要。
Ironic 如何提供帮助
Ironic 作为 OpenStack 项目诞生,旨在取代 Nova(OpenStack 计算实例项目)中包含的原始裸机驱动程序。它允许运营商配置裸机,而不是虚拟机。Ironic 与堆栈的其余部分完全集成,这主要归功于 Nova 的虚拟化驱动程序,该驱动程序使 CLI 对最终用户完全透明。它还可以与 OpenStack 的其他项目集成,如 Neutron(网络即服务)、Glance(机器镜像管理)和 Swift(对象存储)。
Ironic 提供通用的驱动程序(“接口”),支持 IPMI 和 Redfish 等标准,用于管理任何类型的裸金属机器,无论品牌如何。与此同时,它也获得了不同厂商的官方支持,这些厂商不仅帮助维护 Ironic 代码库,还维护包含在 Ironic 代码中的他们自己的接口,以提供与其特定功能完全兼容性。
Ironic 使用 Python 开发,是开源的,并且使用 gerrit7 进行代码审查。为了确保代码的可靠性,Ironic 使用功能强大的 Zuul8 CI 引擎工具来运行基本的单元和功能测试,并使用先进的虚拟化技术模拟裸金属机器,以便能够运行更复杂的测试,包括不同的部署场景、升级和多节点环境。
Ironic 自从“仅仅”是一种向 OpenStack 用户提供裸金属机器的方式以来,已经不断发展和壮大,找到有效方法成为一个独立的裸金属即服务系统,能够提供与完整硬件管理应用程序相同的功能。
强大的 API
Ironic 是 API 驱动和 API 优先的,它包含一组完整的 RESTful API,提供通用的、与厂商无关的接口,允许对裸金属机器进行整个生命周期的配置和管理,从注册到退役。它考虑到可能的多次重新配置和同一设备的重复使用,即节点可以在其生命周期内为不同的用例重新配置。
Ironic API 提供的功能列表(不完全):
- 自动发现,以自动注册裸金属机器(“节点”)到 Ironic
- 硬件内省,以收集节点硬件信息并将其存储在 Ironic 数据库中
- 硬件组件的基准测试和健康检查
- 清理,在部署操作系统之前提供一个已清除的节点
- 配置和配置,包括自定义镜像安装
- 直至节点退役的生命周期结束支持
工具
此处描述的所有工具都以某种形式使用 Ironic 来配置和管理裸金属主机。
TripleO9
一个全面的工具,用于部署完整的 OpenStack 环境。Ironic 用于部署和管理构成云基础设施基础的裸金属主机,以及操作网络交换机配置,以及集成在 OpenStack 云中的云裸金属主机提供商。
Metal310
一个裸金属配置和启用项目,旨在为管理裸金属主机提供 Kubernetes11 原生的 API。该工具包括一个 Bare Metal Operator(Metal3 SDK 生成的堆栈)作为组件,并建议将 Ironic 作为可选模块包含在内,以驱动机器实例。请注意,Metal3(发音为“metal cubed”)正在添加支持,以启用从 Cluster API 对裸金属主机的外部管理,后者再次使用 Kubernetes 的运营模型,但侧重于使用自定义资源定义 (CRD) 的不同的插件云控制器,以支持容器化的控制平面,例如 OpenStack、Azure、Amazon Web Services、Google Cloud 等。在这种用例中,第一个支持的裸金属驱动程序是 Ironic。 很大程度上,这种 ironic 的使用一直集中在 OpenShift Container Platform 的安装上,但社区目前正在发展壮大。
Airship12
一套帮助配置和管理云基础设施的工具,从裸金属主机开始。在 Airship 2.0 中,Ironic 通过 Metal3.io 作为裸金属配置组件集成在 Airship 平台中。
Bifrost14
一个基于 Ansible playbook 的工具,可帮助使用预定义的镜像和独立的 Ironic 部署裸金属服务器。
Kayobe15
一个套件,将不同的工具(如之前提到的 Bifrost 和 Kolla)结合在一起,以便能够在裸金属之上用容器部署 OpenStack 服务。Kayobe 配置和工作流程都由 Ansible 驱动,在每个级别提供一致的接口。
客户端
OpenStackSDK16
一个通用的 OpenStack 客户端库,用于构建与 OpenStack 云服务交互的客户端。它有一个专门的裸金属模块,该模块与 Ironic 中开发的最新功能保持最新。
Gophercloud17
这是 OpenStack SDK 的等效版本,但适用于 golang。它允许 go 开发者直接与 OpenStack 云交互,并支持包括 Ironic 在内的各种服务。
Ironicclient18
官方客户端,用 python 编写。它提供了一个 API 模块,即 ironicclient 本身,用于构建客户端,例如官方 openstackclient,它包括一个与 Ironic 交互的裸金属子集指令,以及一个独立的 CLI,允许与 Ironic 交互而无需安装 openstackclient 本身。
自动化
Ansible19
开源声明式自动化工具,用于管理配置和部署。它与平台无关,并且可以通过用 Python 编写的模块进行高度定制。Ironic 提供了一组与它一起使用的模块。
Terraform20
“基础设施即代码”开源工具,允许用户使用自己的配置语言 (HCL) 定义和配置基础设施。它支持多个云提供商,包括 OpenStack。Metal3 开发了自己的 terraform 提供程序,用于与 Ironic 一起使用。
使用模式
集群安装
虽然越来越多的应用程序正在迁移到云解决方案,但安装和管理底层云的问题变得更加重要。在成为集群的一部分之前,硬件必须以一致且有效的方式进行配置和配置,同时仍然允许一定程度的特定于站点的自定义。
为了解决这些问题并帮助在 OpenStack 社区内创建集群,已经构建了多个工具,这些工具建立在 Ironic 之上,以支持特定的工作流程案例,从批量基本操作系统安装(Bifrost)、OpenStack 集群部署(TripleO 和 Kayobe)到 Kubernetes(Metal3)。
集群扩展
现有集群的扩展需要集成到现有环境中。这要求有关新硬件以及物理连接的信息可供应用程序和执行此扩展的人员使用。这种活动几乎可以描述为对硬件进行检查的行为,以启用此验证。此外,Ironic 中的“清理”框架提供的其他操作也可能需要确保新硬件与现有硬件的行为一致。
裸机即服务
虽然虚拟机和容器可以替代许多应用程序的硬件,但仍然存在必须向云解决方案的最终用户提供裸金属实例的情况。以与云的其他功能一致的方式提供它们可以提供流畅的用户体验并允许更简单的自动化。为了实现这一点,Ironic 可以作为 OpenStack Compute 服务 (Nova) 的后端,并与 OpenStack Networking (Neutron)、OpenStack Image 服务 (Glance) 和 OpenStack 块存储 (Cinder) 的可选集成将裸金属体验尽可能地接近虚拟机。
此外,将裸金属机器暴露给潜在的不受信任的租户,对安全方面提出了强烈要求。Ironic 的可插拔清理过程提供了一种在租户之间将裸金属机器返回到已知状态的能力,包括从硬盘驱动器中删除信息、更改网络和/或重置固件设置等操作。
裸机上的容器
容器和容器编排框架,例如 Kubernetes,解决了云原生应用程序对快速配置更改、平滑升级或自动扩展的需求。虽然这些集群通常建立在虚拟机之上,但这可能会给底层云基础设施增加额外的成本和复杂性,或者由于虚拟化税而引入不希望的性能损失。像 Ironic 提供的裸金属管理 API,允许从虚拟到裸金属集群的透明移动作为底层基础设施。一个例子是 OpenStack Magnum 作为集群编排引擎,其中计算端点将根据指定的模板实例化虚拟或物理实例。同样,这样的 API 可用于与 Metal3 for Kubernetes 等其他配置工具集成,从而在部署容器化应用程序时消除中间的虚拟化层。
边缘设备管理
边缘架构对硬件管理提出了新的挑战。通过本质上不安全的介质进行的远程连接会阻止或限制许多传统的裸金属配置和管理技术的使用,例如 PXE 或 IPMI,同时加密和身份验证在每个阶段都成为要求。Redfish 是一种由分布式管理任务组 (DMTF) 开发的开放裸金属管理标准,它可以通过在久经考验的 HTTPS 协议上提供一组强大的功能来解决许多这些挑战。最近在 Ironic 中实现的虚拟介质设备部署,允许完全绕过初始不安全且不可靠的部署阶段,仅使用 TLS 加密通信。
硬件故障管理
随着数据中心的扩展以及部署管理的设备数量的增加,硬件故障已成为常态。识别故障设备、在 Ironic 中标记它并替换它(同时保留已替换组件的身份)是日常运营的必需品。
案例研究
CERN
物质是由什么构成的?为什么物质比反物质多?大爆炸后最初的时刻发生了什么? 寻找这些以及其他关于我们宇宙的基本问题的答案是 CERN23,欧洲核子研究组织的使命。
为了实现其使命,CERN 在日内瓦附近的法瑞边境建造并运营了世界上最大的粒子物理实验室。在这里,该组织提供并维护着分层粒子加速器、实验探测器及其周围的基础设施,以使全球数千名科学家能够增进我们对宇宙的构成方式和运作方式的了解。
为了分析这些实验产生的数据,需要全球 200 多个计算中心联合他们的计算能力在全球大型强子对撞机计算网格中。CERN 数据中心是这个科学基础设施的中心,拥有超过 15,000 台服务器中的约 230,000 个内核。CERN 计算资源中 90% 以上由基于 OpenStack 的私有云提供,CERN IT 部门自 2013 年以来一直在生产环境中运行该部署。
最近完成云服务的服务产品组合有几个原因,其中一个系统用于裸金属配置
- 简化物理机器的采购和配置工作流程
- 将裸金属服务器集成到资源核算中
- 满足特殊用例并启用新的用例
工作流程简化:CERN 的硬件生命周期
在物理机器进入 CERN 生产之前,新硬件必须经过验证、老化和基准测试。这些步骤背后的原因包括:
- 确保硬件符合技术规范
- 识别损坏的组件,例如故障的 CPU
- 发现交付中的系统错误,例如固件问题
- 诱发早期故障
一旦服务器通过了这个过程,它们就会分配给最终用户。通常通过在我们内部数据库之一中更改所有权来完成。然后由最终用户安装、配置和监控硬件。如果用户不再需要他们的机器,或者机器达到其使用寿命,它们将返回给采购团队(通过撤销所有权更改)。然后对机器进行清理,例如擦除磁盘或重置 IPMI 密码,并分配给新的用例、捐赠或处置。图 1 概述了此生命周期中的步骤。

图 1:采购和资源分配工作流程。
整个过程本质上很复杂,但除了依赖各种内部编写的工具外,还在各个步骤中需要人工干预。将 Ironic 作为物理资源管理的主要工具引入,旨在减少复杂性、维护负载以及在流程中取消阻塞某些步骤所需的人工干预。
在最初注册到我们的网络数据库后,这些节点现在已被注册到 Ironic,它可以进行技术规范的验证(通过检查规则)、运行磨合和基准测试(作为手动清理步骤),并且与 Nova 结合使用,简化了分配和重新分配过程。物理机的申请者将使用一个表单来申请计算资源,并通过他们用于虚拟机的相同的 OpenStack 实例创建过程获得他们的物理机。如果不再需要机器,可以销毁物理实例,这将触发 Ironic 的自动清理。机器被标记为可用,可用于新的用例。最终的退役(更彻底的清理)也变成了一个手动清理步骤。凭借 Ironic 的状态机、其清理框架以及与 Nova 的集成,资源配置工作流程的大部分简化为几个 API 调用。
资源会计
几年前,随着 CERN IT 部门引入基于 OpenStack 的私有云服务,所有服务器都必须虚拟化的策略得以确立。使用 OpenStack 作为计算资源配置和管理的统一窗口,诸如“哪个服务正在使用多少资源?”之类的会计问题变得更容易回答。
由于物理机器是在 OpenStack 之外分配的,因此必须维护和查阅一个单独的来源才能获得完整的会计细节。当物理机器被分配给新的用例时,情况变得更加复杂,因为这需要被记录和跟踪,以便始终拥有准确的资源分配情况。
通过在 Nova 中管理并在 Ironic 中配置的物理实例,整体会计的来源数量减少到一 个。服务器更改用例不再需要主动跟踪,因为 Ironic 中的相应节点将在已知的项目中拥有实例,并可以相应地进行归因。使用 Ironic 可以使资源会计更简单、更一致。
由于 Ironic 还支持“采用”,即无需通过 Nova 或 Ironic 实例化即可集成已存在的服务器,因此无需等待整个机队更换即可获得物理基础设施及其对应分配的完整视图。
特殊和新的用例
CERN IT 部门的一些服务免于上述“优先虚拟化”策略。这包括提供计算基础设施的服务,即 OpenStack 计算节点(但不是 OpenStack 控制平面),以及存储服务,例如磁盘或数据库服务器,或处于标准网络连接之外或由于引导或安全原因而不能依赖其他服务的关键任务服务。
然而,存在一些不需要上述任何要求的用例,但仍然有必要将这些服务放在物理机器上。一个例子是大型强子对撞机 (LHC) 实验的代码校准和性能监控服务。为了满足分析 CERN LHC 实验产生的大量 PB 级数据所需的计算需求,并以最有效的方式利用现有资源,必须尽可能地优化代码。为了检测代码、操作系统或编译器更改的影响,需要一个提供可重现结果的稳定平台。由于我们 OpenStack 部署中的虚拟机在 CPU 方面存在过度承诺,因此虚拟机不能提供这样一个稳定的平台(即使没有过度承诺,减少层数并删除虚拟化可能也是可取的)。其他物理服务器是明智选择的用例可能包括具有 GPU 或我们 HPC 集群中专用硬件的服务器。
CERN IT 部门的 OpenStack 云服务还支持通过 OpenStack Magnum 创建容器集群。虽然该服务最初支持 Swarm 和 Mesos,但如今绝大多数这些集群都使用 Kubernetes。然而,Kubernetes 集群是通过 OpenStack Heat 在虚拟机之上创建的。这增加了一个额外的(不一定期望的)抽象层。借助 Ironic,现在可以仅使用物理机器或甚至以混合模式(只有主节点是虚拟机,而从节点是物理机器)直接创建这些集群。CERN IT 部门的批量处理服务是使用这种方法的应用程序的一个例子。通过 Nova 和 Ironic 进行虚拟和物理机器配置的结合,可以最大限度地有效利用分配的资源。
当前服务状态和未来计划
基于 Ironic 的 CERN 裸机配置已经投入生产大约两年了,目前已注册超过 5,000 个节点。通过仅进行少量修改,例如利用我们的中央 PXE 基础设施而不是在 Ironic 控制器上管理的一个,我们使用上游版本并已成功多次升级 Ironic。

图 2:CERN IT 部门使用的 Ironic 仪表板。
虽然 Ironic 在其当前配置中已经实现了上述大部分目标,并已确立为管理 CERN IT 部门中物理服务器整个生命周期的框架,但仍有几个领域我们可以期待进一步的收益。除了采用现有的物理节点外,目前正在演进的图形控制台支持、Redfish 作为 IPMI 后继者的引入以及硬件清单系统的开发,与 Ironic 紧密合作对 CERN IT 部门的资源配置服务特别重要。
https://superuser.openstack.org/articles/Ironic-bare-metal-case-study-cern/
StackHPC24
Ironic 中的软件 RAID 支持
Ironic 运行在一个奇妙的世界里。Ironic 的每个版本都引入了更多对虚拟化抽象的创新实现。然而,裸机被包裹在硬件定义的具体事物中:没有软件定义云中等价物的设备和配置。为了存在,Ironic 必须提供纯粹的抽象,但为了成功,它还必须提供现实世界的规避方案。
几十年以来,HPC 系统管理员的传统角色包括部署裸机,有时甚至是大规模部署。为了确保可重复性、可扩展性和效率,自动化对于超过微不足道的系统数量至关重要。到目前为止,这种自动化已在特定领域的方式中发展,并加载了简化假设,从而能够从最少的服务配置和管理大规模基础设施。Ironic 是第一个以云范例定义裸机基础设施配置的框架。
说到理论:使用硬件一直有点棘手,不如预期那样可预测或可靠。支撑现代敏捷口号的软件定义基础设施,通过数量级加速了与硬件服务的交互。Ironic 努力在不可靠的情况下交付结果(最大限度地减少要求数据中心中的某人用大棍子敲打机器的需求)。
用于地震分析的 HPC 基础设施
作为地震处理行业的领导者,ION Geophysical25 维护着一个超大规模的生产 HPC 基础设施,并采用分阶段采购模式,导致多个世代的硬件同时在生产环境中处于活动状态。现场故障和更换进一步增加了差异性。在多个硬件配置上提供一致的软件环境可能是一个挑战。
ION 正在将本地 HPC 基础设施迁移到 OpenStack 私有云。OpenStack 基础设施使用 Kayobe 部署和配置,Kayobe 是一个将 Ironic(用于硬件部署)和 Kolla-Ansible(用于 OpenStack 部署)集成到 Ansible 框架中的项目。Ansible 为从物理层到应用程序工作负载的一切提供一致的接口。
这个过程始于一些较旧一代的 HPE SL230 计算节点,并将控制权转移到 OpenStack 管理。每个节点有两个 HDD。为了满足工作负载要求,这些被配置为两个 RAID 卷 - 一个镜像(用于操作系统),一个条带化(用于工作负载的暂存空间)。
每个节点还具有硬件 RAID 控制器,并且 Ironic 的标准做法是利用它。然而,在付出相当大的努力之后,发现
- 硬件 RAID 控制器使用 ssacli 工具进行管理。
- 该 RAID 控制器需要专有的内核驱动程序。
- 该驱动程序不可用于最新的 CentOS 版本。
- 服务器硬件包括一个“个性化板”,该板在许多系统上悄无声息地发生故障,从而阻止了这些系统上硬件 RAID 的自动化重新配置。
考虑到这些和其他因素,决定硬件 RAID 控制器无法用于此迁移。幸运的是,Ironic 开发了一种基于软件的替代方案。
配置为软件 RAID
Linux 服务器通常使用镜像 RAID-1 卷部署其根文件系统。此要求体现了 Ironic 项目中固有的紧张关系。虚拟化的抽象要求将客户操作系统视为黑盒,但软件 RAID 实现是 Linux 特定的。然而,不支持 Linux 软件 RAID 将限制主要用例。在不失去 Ironic 的通用能力的情况下,客户操作系统“黑盒”在像这样特殊的案例中变成了白盒。CERN 的最新工作为 Ironic Train 版本贡献了软件 RAID 支持。
CERN 团队已在其技术博客上记录了软件 RAID 支持26。
在初始实现中,软件 RAID 功能受到限制。裸机节点被分配了一个持久的软件 RAID 配置,每当节点被清理并用于所有实例部署时都会应用。之前 StackHPC 团队开发实例驱动的 RAID 配置27 的工作尚未用于软件 RAID。然而,当前的驱动程序实现为 Kayobe 的云基础设施部署提供了恰到好处的功能。
方法
Ironic 中的 RAID 配置在 Ironic 管理员指南中描述得更详细。这里提供了一个高级概述。
在 Ussuri 版本之前,不支持使用 UEFI 启动软件 RAID,因此在部署 Train OpenStack 时必须配置 BIOS 模式启动。
根据 CERN 博客文章中的规定,配置了一系列计算节点,每个节点有两个物理旋转磁盘。在每个节点上的 RAID 配置集中指定了两个逻辑磁盘;第一个用于操作系统,第二个供 Nova 用作虚拟机的暂存空间。
{
"logical_disks": [
{
"raid_level": "1",
"size_gb" : 100,
"controller": "software"
},
{
"raid_level": "0",
"size_gb" : "MAX",
"controller": "software"
}
]
}
然后使用以下清理步骤应用 RAID 配置
[{
"interface": "raid",
"step": "delete_configuration"
},
{
"interface": "deploy",
"step": "erase_devices_metadata"
},
{
"interface": "raid",
"step": "create_configuration"
}]
选择了 RAID-1 设备用于操作系统,以便在单个磁盘发生故障时,虚拟机仍然可以正常运行。RAID-0 用于暂存空间,以利用该配置提供的性能优势和额外存储空间。应该注意的是,此配置特定于预期用例,可能不适用于所有部署。
如 CERN 博客文章所述,mdadm 包被安装到 Ironic Python Agent (IPA) ramdisk 中,用于在清理期间配置 RAID 阵列。mdadm 也被安装到部署镜像中,以支持将 grub2 引导加载程序安装到物理磁盘上,以便在其中一个磁盘发生故障时从任一磁盘加载操作系统。最后,mdadm 被添加到部署镜像 ramdisk 中,以便当节点从磁盘启动时,它可以转到根文件系统。
开源,开放开发
作为一个开源项目,Ironic 依赖于蓬勃发展的用户群为项目贡献。我们的经验涵盖了软件 RAID 驱动程序以前未使用的硬件:不可避免地,发现了新的问题。
第一个观察结果是,在对 56 个节点的样本进行清理时,大约 25% 的节点上的 RAID 设备配置失败。失败的节点记录了以下消息
mdadm: super1.x cannot open /dev/sdXY: Device or resource busy
其中 X 是 a 或 b,Y 是 1 或 2,分别表示物理磁盘和分区号。这些节点以前已使用软件 RAID 部署,无论是通过 Ironic 还是其他方式。
内核日志检查显示,在所有情况下,被标记为忙的设备已被内核从阵列中弹出
md: kicking non-fresh sdXY from array!
被弹出的设备可能未同步,并显示在 /proc/mdstat 中作为 RAID-1 阵列的一部分。另一个驱动器已被擦除,缺失了输出。结论是弹出的设备绕过了旨在删除所有先前配置的清理步骤,并在 create_configuration 清理步骤期间阻止了阵列的形成。
为了使清理成功,应用了一个手动解决方法,停止了此 RAID-1 设备,并在超块中清除了签名
mdadm --zero-superblock /dev/sdXY
移除所有预先存在的状态极大地提高了 Ironic 创建软件 RAID 设备的可信度。剩下的问题是为什么某些服务器出现此问题,而另一些服务器没有。进一步检查显示,虽然许多磁盘都很旧,但没有报告 SMART 故障。这些磁盘通过了自检,并且虽然通常很接近,但尚未超过其平均故障间隔时间 (MTBF)。除了从阵列中移除设备外,内核未报告任何故障迹象。主动寻找错误,例如运行 badblocks 等工具来测试整个磁盘介质,表明只有极少量的磁盘存在问题。基准测试、老化测试和异常检测可能更早地识别出这些设备。
进一步的研究可能有助于我们确定表现出这种行为的磁盘是否存在其他故障。另一个调查方向是增加内核中驱动器的重试和超时等阈值。
观察到的第二个问题发生在节点从 RAID-1 设备启动时。这些节点运行 IPA 并部署基于 Centos 7.7.1908 的镜像,内核版本为 3.10.0-1062,会显示降级的 RAID-1 阵列,并显示与失败的清理周期中相同的消息。
md: kicking non-fresh sdXY from array!
通过对节点运行 Kayobe 自定义 playbook,将 sdXY 重新添加到阵列中,开发了一种解决方法。在所有情况下,被弹出设备都会与 RAID 设备重新同步。RAID 阵列的状态使用 OpenStack Monasca 监控,该监控从最近的发布候选版本的 Prometheus Node Exporter 摄取数据,其中包含一些关于 MD/RAID 监控的增强功能。28 可以使用简单的仪表板可视化软件 RAID 状态。

图:Monasca MD/RAID Grafana 仪表板。左上角的图表显示了每个 RAID 设备上同步的块的百分比。可以看到一个 RAID-1 阵列在设备被强制故障并重新添加后恢复,以模拟磁盘的故障和更换。不幸的是,由于 Ironic 不支持软件 RAID的名称字段29,因此目前无法区分每个节点上的 RAID-0 和 RAID-1 设备。因此,RAID-0 和 RAID-1 阵列的名称在 md126 和 md127 之间随机交替。右上角:模拟的故障设备在几秒钟内可见。这是生成警报的一个很好的指标。左下角:阵列重建时,设备被标记为正在恢复。右下角:未启动手动重新同步。该设备被 MD/RAID 视为正在恢复,未在此图中显示。
这两个问题的根本原因尚未确定,但它们很可能相关,并且与这些磁盘和内核 MD/RAID 代码之间的交互有关。
开源,开放社区
与硬件交互的软件很快就会建立起大量的“案例法”和例外情况及解决方法。像 Ironic 这样的开放项目在用户成为贡献者时才能生存,甚至蓬勃发展。没有利用社区贡献的同类项目最终都未能成功。
CERN 团队(以及 OpenStack 社区中的其他成员)做出的最初贡献使 StackHPC 和 ION Geophysical 能够以最佳方式部署用于地震处理的基础设施。StackHPC 在此基础上增加了经验、文档改进以及更强大的 RAID 设备创建处理能力。即使是小的贡献,在分享出来后,也有助于进一步加强项目。
https://superuser.openstack.org/articles/openstack-Ironic-bare-metal-program-case-study-stackhpc/
SuperCloud
简介
SuperCloud 是一种旨在结合超级计算和云计算的系统架构,兼具两者的优势,避免两者的缺点。它由 Jacob Anders 提出,当时他为 CSIRO 工作。SuperCloud 概念验证在温哥华(2018 年)的 OpenStack Summit 和丹佛(2019 年)的 Open Infrastructure Summit 上展示,并为建立性能基准和验证各种基础设施即代码工作流程(从裸机按需 HPC 到临时虚拟机)提供了一个有价值的测试平台。
原理
传统上,超级计算机完全专注于性能(因此直接在硬件上运行),而牺牲了它们提供的灵活性。在超级计算环境中,用户可以期望获得出色的性能,但很少有奢侈品可以带来他们自己的操作系统镜像或要求他们的工作负载在隔离的网络环境中运行。另一方面,云计算系统为用户提供几乎无限的灵活性,但通常是通过使用虚拟化来实现的,而虚拟化通常会带来显著的性能损失,使这些系统不太适合托管高性能计算 (HPC) 工作负载。
实施
为了应对这些挑战,SuperCloud 建立在 Ironic 裸机服务之上,并将其与 InfiniBand 软件定义网络相结合。该系统可以直接在硬件上配置云实例,无需虚拟化,从而达到先前仅在经典 HPC 系统上看到的性能水平。它能够在这样做同时,使用户能够运行所需的任何操作系统和工作负载,在软件定义网络中配置资源,这些网络可以像在经典虚拟化云环境中一样隔离、私有、共享或公开访问。
SuperCloud 是基础设施即代码工具的基础。这有可能使用户能够通过单个统一的 API 集成地请求裸机计算、网络、存储和软件资源。这是整合当今孤立的软件定义网络 (SDN)、软件定义存储 (SDS) 和软件即服务 (SaaS) 岛屿并使 IT 团队进入构建系统的新范例——软件定义计算的关键能力。在这个新的范例中,HPC 集群管理软件、作业调度器和高性能并行文件系统会向上移动堆栈,并成为可以与运行虚拟机和容器节点的超visor 并行运行的云原生应用程序,所有这些都包含在一个标准操作系统环境中。与此同时,HPC 计算和 HPC 存储变得更加异构、灵活和动态——不仅可以持续提供最佳性能,还可以快速适应科学界不断变化的需求,从而应对缺乏灵活性带来的挑战。
性能
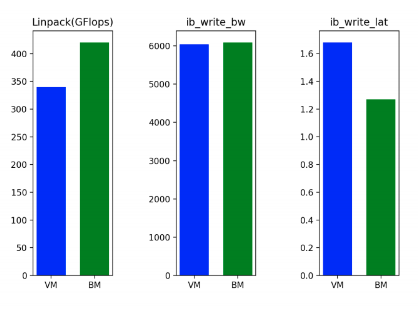
在 SuperCloud 环境和配置中,初步基准测试显示出有希望的结果——在运行 Linpack 时,与虚拟机相比,CPU 性能提高了约 19%。由于虚拟化环境中使用 SRIOV 技术,互连带宽在裸机上仅略高(约 1%),但互连延迟在裸机上明显优越(约低 23%)。以下图表总结了这些测试。
示例工作负载
为了展示裸机云的功能,请考虑以下示例用例
裸机上的基础设施即代码
说云计算的诞生源于对自动化的需求并不为过。应用程序开发人员需要一种通过一组 API 端点以编程方式请求计算、网络和存储资源的方法,以便他们可以轻松部署和扩展应用程序,而无需基础设施团队的参与。虚拟化在很大程度上通过创建一个方便的抽象层来帮助完成这项任务,但是,直到最近,裸机部署的情况并不那么简单。虽然存在许多完全或部分自动化的硬件部署方法,但大多数方法都有限制和/或通常特定于平台,并且无法匹配云环境的功能集。
将 Ironic 裸机配置添加到 OpenStack 极大地改变了这种格局。现在,为虚拟化云开发的标准基础设施即代码工具可以用于配置裸机。能够重用现有工具和抽象非常强大,如下例所示。
ElastiCluster - 裸机按需 HPC
Elasticluster (https://elasticluster.readthedocs.io/en/latest/) 是苏黎世大学开发的一个软件包,它可以按需将软件定义的 HPC 集群部署到 EC2、GCE 和 OpenStack 云。虽然 ElastiCluster 最初是为虚拟化实例设计的,但基础设施即代码方法和相关的抽象使其很容易适应在裸机上运行。唯一需要的修改是为集群节点指定“裸机”flavor,并调整超时值以适应裸机系统较长的启动时间。
通过少量修改,基于 OpenStack 的按需 HPC 可以使用速度更快的裸机计算,而不会牺牲网络多租户。这是 Ironic 允许在新的、性能更高的上下文中重用现有代码的一个很好的例子。
临时虚拟机
从设计上讲,SuperCloud 系统没有主要的虚拟化能力;它仅是裸机。但是,能够运行裸机计算实例意味着可以添加辅助虚拟化能力(如果需要)。可以通过创建连接到内部 API 网络的裸机实例并相应配置 nova-compute 服务来配置超visor。将基础设施即代码能力与裸机配置相结合的主要好处是能够构建和维护一个硬件池,可以快速轻松地重新配置以满足各种不同的角色。虽然用户可能希望在 ElastiCluster 系统中运行多个高性能服务器,但另一组节点可以运行弹性超visor 或容器节点。这有可能提高资源利用率并降低通常与不同工作负载需要不同类型的服务一起运行相关的运营开销。
Red Hat30
正如 OpenStack Baremetal Logo Program 案例研究 SuperUser 文章31 中所述,Redhat 使用 Ironic 的主要原因是帮助支持客户自动化安装其 OpenStack Platform32 产品,这也很合乎逻辑,因为使用了 TripleO33 项目。这种使用随着 Metal334 项目的增长,以帮助促进 RedHat 的 OpenShift35 产品的自动化安装。
但是,Ironic 不仅使我们的安装工具更容易配置裸机硬件,还提供了一个 API 和机制来支持运行云中的各种用例,最终允许云用户以 API 驱动、可重复且可靠的方式访问他们需要的专用资源。
Airship36
Airship 的目标是使操作员能够以弹性云的形式可预测地交付原始基础设施,并有效地管理由此产生的平台的生命周期,遵循云原生原则,例如服务的实时升级,而不会导致停机。为了实现这一点,Airship 集成了最佳的开源工具,为基础设施管理提供了一个易于使用、灵活和声明式的界面。
这个难题的基本部分是裸机服务器的配置和管理。Airship 最初使用围绕传统基于包的裸机配置工具(MaaS)的声明式包装器。但是,这并没有提供所需的不可变性和基于镜像部署的可预测性。为了解决这个问题,Airship 2.0 集成了 Metal3 项目。Metal3 呈现了裸机的声明式模型,并驱动 Ironic(以独立模式)有效地实现配置。为了进一步以声明方式建模 Kubernetes 集群,Airship 使用 Kubernetes 集群 API (CAPI)。CAPI 通过为公共云提供商、OpenStack 集群和裸机配置提供实现,扩展了 Airship 的目标,成为灵活、通用工具。
从 Airship 的角度来看,最终结果是 CAPI 允许它跨这些不同的环境一致地管理基础设施和工作负载。这为诸如在私有裸机集群和弹性公共云之间共享容器化网络功能 (CNF) 工作负载等用例打开了大门,以及许多以前不可能实现的用例。Airship 和 Metal3 社区密切合作,以确保 Metal3 作为 Kubernetes 集群 API 的裸机提供程序无缝集成。
Airship 对裸机能力的需求源于本文档中其他地方提到的许多好处——特别是需要从物理资产中榨取每一丝性能,以及将基础设施物理位置靠近最终用户。这些是成功、低延迟 5G 网络的关键要素,这是 Airship 的初始关键用例。此外,如边缘用例模式中详细所述,通过 WAN 驱动安全、远程配置的能力促使 Airship 2.0 采用基于 Redfish 的引导过程。
最后,如果没有利用它的工作负载,基础设施毫无意义。Airship 提供了一个声明式 YAML 界面和 CLI 来管理任何基于 Helm 或原始 Kubernetes 清单的工作负载的生命周期,并将其与服务器、Kubernetes 节点和网络配置的管理统一起来。它提供了 Treasuremap 项目,其中包含用于常见工作负载(如 OpenStack、日志记录和监控以及数据库)的可重用配置。Airship 2.0 正在将 Treasuremap 重新构建为操作员可以快速使用和自定义以满足其独特需求的意图库。
更多!
许多其他公司在生产中使用 Ironic,如各种 Superuser 文章中所记录。
Platform939
Platform 9 提供基于软件即服务的基础设施,用于部署和运营 KVM、VMware 和公共云环境的 OpenStack 混合云。
https://superuser.openstack.org/articles/Ironic-bare-metal-case-study-platform9/
ChinaMobile40
ChinaMobile 是中国大陆领先的电信供应商。
VEXXHOST41
VEXXHOST 为全球客户提供基础设施即服务 OpenStack 公有云、私有云和混合云解决方案,客户规模从小企业到大型企业不等。
https://superuser.openstack.org/articles/openstack-Ironic-bare-metal-program-case-study-vexxhost/
未来
开源基础设施
当我们审视基础设施的基础时,存在着共同的模式。这些模式在很大程度上是由于标准和成为标准或事实标准的运营方式而存在的。从某种意义上说,这归结为形式追随功能,就像功能追随形式一样。几乎可以将其看作是一种阴阳关系或扭副电缆的每个导体。很难相信 1881 年发明的扭副电缆42 至今仍在被使用,因为它提供了一个极好的基础。
因此,可以想象一个未来,这些模式将继续存在,因为没有单一的供应商或供应商,而且我们的社会也不可能存在。现实地说,技术所能采取的唯一途径是进一步的持续创新和民主化。这类似于扭副电缆在它存在的多年里不断改进质量以满足其构建在其基础上的需求。
由于没有单一的供应商或解决方案,并且人类天生具有独特性,因此开放的必要性得以实现。开放提供共同的基础、公平的竞争环境。共同的需求是合作的基础,这强调了开放性的必要性。最终,无论我们构建可组合的系统、飞往月球的飞船还是启动用猫殖民火星的任务,与开放基础设施合作仍然是成功的必要条件。
短期内
虽然我们都可能希望用猫来填充火星,但基本的访问和管理层是必要的,它们将作为结构和机制的基础。像Redfish这样的标准只会为希望参与这项努力的供应商和消费者带来一致性,通过认识到通用手段可以更快、更有效地利用设备。但这并不否定其他与标准相悖的努力,因为它们也是创新的引擎。
当我们展望裸机管理时,市场驱动的通用功能集为每个人带来共同的价值。这就是像Ironic这样的工具带来巨大价值的地方,旨在使用户和操作员能够通过开放的通用机制来利用通用功能集。
与任何努力一样,这需要对Ironic的贡献者付出大量的奉献和承诺。共同的用例、共同的手段和共同的需求将继续推动我们前进。
感谢
特别感谢那些为本文贡献了文字、评论和问题的各位。如果没有大家的努力,这份论文是不可能完成的。
贡献者
本文包含许多个人(已知和未知)的文字,因为本文在社区内可供匿名编辑。
한승진, SK Telecom
Jacob Anders, CSIRO
Alex Bailey, AT&T
Pete Birley, AT&T
Manuel Buil, SUSE
Ella Cathey, Cathey.Co
Chris Dearborn, Dell Technologies
Fatih Degirmenci, Ericsson
Ilya Etingof, Red Hat
Chris Hoge, OpenStack Foundation (OSF)
Chris Jones, Red Hat
Arkady Kanevsky, Dell Technologies
Julia Kreger, Red Hat
Simon Leinen, SWITCH
Matt McEuen, AT&T
Noor Muhammad Malik, Xflow Research
Quang Huy Nguyen, Fujitsu
Richard Pioso, Dell Technologies
Riccardo Pittau, Red Hat
Prakash Ramchandran, Dell Technologies
Doug Szumski, StackHPC
Dmitry Tantsur, Red Hat
Stig Telfer, StackHPC
Kaifeng Wang, ZTE
Arne Wiebalck, CERN
Wes Wilson, OpenStack Foundation (OSF)
参考文献
- https://www.intel.com/content/www/us/en/products/docs/servers/ipmi/ipmi-home.html
- https://www.dmtf.org/standards/redfish
- https://cobbler.github.io
- https://theforeman.org
- https://maas.io/
- https://meltdownattack.com/
- https://www.gerritcodereview.com/
- https://zuul-ci.org/
- https://docs.openstack.org/tripleo-docs/latest/
- https://metal3.io/
- https://kubernetes.ac.cn/
- https://www.airshipit.org/
- https://thenewstack.io/metal3-uses-openstacks-ironic-for-declarative-bare-metal-kubernetes/
- https://thenewstack.io/metal3-uses-openstacks-ironic-for-declarative-bare-metal-kubernetes/
- https://docs.openstack.org/bifrost/latest/
- https://docs.openstack.org/kayobe/latest/index.html
- https://docs.openstack.org/openstacksdk/latest/
- http://gophercloud.io/
- https://docs.openstack.org/python-ironicclient/latest/
- https://ansible.org.cn/
- https://www.terraform.io/
- https://github.com/openstack/puppet-ironic
- https://puppet.com/
- http://home.cern
- https://www.stackhpc.com/
- https://www.iongeo.com/
- http://techblog.web.cern.ch/techblog/post/ironic_software_raid/
- https://www.stackhpc.com/bespoke-bare-metal.html
- https://github.com/prometheus/node_exporter/tree/v1.0.0-rc.1
- https://docs.openstack.org/ironic/train/admin/raid.html#optional-properties
- https://#/en
- https://superuser.openstack.org/articles/openstack-ironic-bare-metal-program-case-study-red-hat/
- https://#/en/technologies/linux-platforms/openstack-platform
- http://tripleo.org/
- https://metal3.io/
- https://www.openshift.com/
- https://www.airshipit.org/
- https://www.verizonmedia.com/
- https://superuser.openstack.org/articles/how-verizon-media-rocks-bare-metal/
- https://platform9.com/
- https://www.chinamobileltd.com/en/global/home.php
- https://vexxhost.com/
- 专利 US244426A - A. G. Bell - 1881年7月 - https://patents.google.com/patent/US244426A/en
- 分布式管理任务组 - Redfish - https://www.dmtf.org/standards/redfish