OpenStack 用于人工智能
OpenStack 和人工智能基础设施的转变
作者:Linux 基金会 AI 和基础设施总经理 Mark Collier回想今天人工智能的发展现状,我记起了未来学家 Sinead Bovell 的一句话:“人工智能正处于互联网 1993 年的阶段。” 这种说法让我感同身受。 就像互联网的早期一样,人工智能已经从研究实验室和初创公司演示发展到每个主要企业、政府和研究机构都在竞相采用的东西。 但这里有一个关键点:这不仅仅是另一波软件浪潮。 这是一次全面的基础设施转变。
每次我们达到像这样转折点时(互联网、云、现在是人工智能),我们都必须回到起点并重新思考基础:计算、存储、网络。 就像过去一样,开源正处于其中。
在过去的 18 个月里,已经清楚人工智能不会仅仅作为我们现有基础设施的副驾驶。 它将要求拥有自己的道路。 今天正在建设的数据中心不仅仅是昨天数据中心的更大版本。 它们从一开始就为高密度 GPU 集群、巨大的电力和冷却需求以及新的延迟敏感型分布式计算模式而设计。 根据麦肯锡的说法,到 2030 年,仅人工智能工作负载预计将增加三倍以上,从而推动全球数据中心容量增加 124 吉瓦。 这不是一个笔误。 这是一种重塑整个行业的规模。
像 Meta 这样的公司已经在建设兆瓦级的园区来训练 LLaMA 等人工智能模型。 Google 每月通过其人工智能基础设施处理一万万亿个 token,仅在过去几个月内使用量就翻了一番。 NVIDIA 呢? 他们正在运行 OpenStack Swift 集群,每天摄取 PB 级的数据来支持内部模型训练。 这一切正在发生,而且速度很快。
现在的挑战是:如果人工智能要扩展,我的意思是真正扩展,它需要能够跟上步伐的软件基础设施。 这就是 OpenStack 发挥作用的地方。
十多年来,OpenStack 一直为地球上最大的云提供动力。 它在沃尔玛、彭博社、中国移动和 CERN 等地方运行数百万个核心。 它经过了多年实际使用和持续演化的考验。 现在,它正在再次演化,这次是为了人工智能。
让我们谈谈正在发生的变化。
人工智能工作负载不仅需要大量的计算,还需要加速计算:GPU、FPGA、ASIC。 OpenStack 对这些的支持在过去几个发布周期中得到了显着成熟。 我们添加了 GPU 感知调度、PCI 直通、NVIDIA 的 vGPU 和 MIG 支持、AMD 的 SR-IOV 以及 GPU 支持实例的实时迁移。 Cyborg 项目正在构建一个一流的加速器管理框架。 这些不是科学项目:它们是经过社区测试和部署到生产环境中的实时功能。
在存储方面,OpenStack Swift 和 Ceph 已经能够处理人工智能训练管道的 PB 级吞吐量。 我们已经看到了实际的例子,例如 NVIDIA 的内部集群,Swift 用于实时流式传输巨大的训练数据集。 随着数据量继续爆炸式增长,这种可扩展、可靠的对象存储将变得越来越重要。
网络是另一个压力点。 分布式训练和低延迟推理对吞吐量、可靠性和设备支持提出了新的要求。 OpenStack 的 Neutron 服务正在跟上步伐,支持高速网络、RDMA、InfiniBand 和虚拟化网络接口。 我们还在继续扩展对边缘异构设备的支持,而人工智能的未来将在很大程度上取决于边缘。
技术要求是真实的,并且正在快速发展。 但如果让我说一下 OpenStack 在这一刻的优势所在,那不仅仅是代码。 而是社区。
与专有平台不同,OpenStack 是由使用它的人构建的。 这意味着当出现新的需求时,例如多租户 GPU 调度或 LLM 编排的代理到代理协议支持时,它不会被放在某个供应商的路线图上,而是在三个季度后才会实现。 它会被构建、审查和合并,然后整个社区从中受益。
我从早期就开始参与这段旅程。 我看着 OpenStack 一次又一次地适应不断变化的需求:首先是满足云 IaaS 的需求,然后是支持容器编排,然后是 HPC。 现在轮到人工智能了。 我们不是从头开始。 过去三个 OpenStack 版本都包含了与 GPU 相关的增强功能。 这是因为用户要求,并且贡献者出现了并使其成为现实。
协作每天都在 IRC、邮件列表中、虚拟 PTG 中以及面对面的峰会上进行。 随着我们进入 Linux 基金会大家庭,这种协作现在扩展到整个开放基础设施和人工智能生态系统,包括 Kubernetes、Kata Containers 等。 OpenStack 正在不断发展并集成到更广泛的开放、可扩展人工智能基础设施运动中。
我们邀请其他人加入我们。 无论您是构建开源推理堆栈的研究人员、在主权云中扩展人工智能的服务提供商,还是在生产环境中试验代理和 LLM 的企业,这里都有您的位置。 OpenInfra AI 工作组和 OpenStack AI SIG 已经根据实际用例塑造了软件的方向。 这份白皮书只是这项工作的一个成果。
我不会假装这一切都已经解决。 我们仍然处于 Andrej Karpathy 称之为“代理十年”的早期阶段。 我们仍然需要做更多的工作来简化推理部署、融合竞争的开源工具链以及扩展边缘人工智能。 但模式是熟悉的。 就像早期的网络和早期的云一样,现在我们需要的是开放协作、清晰的接口以及将控制权交还给构建者的基础设施。
核心场景
场景 1:基础模型训练与服务
重要性: 这是任何希望利用人工智能的组织的基础起点。 可以将其视为建造厨房。 在您可以提供餐点(您的 AI 应用程序)之前,您需要一个可靠的地方来准备食材和烹饪(训练模型)。 此场景解决了最基本的需求:一个稳定且可访问的环境,供开发人员创建和启动 AI 服务。
- 描述: 数据科学家和开发人员被分配 GPU 和 CPU 资源,以便在 Jupyter Notebook 或 Visual Studio Code 等熟悉的环境中开发和训练模型。 训练好的模型随后部署到 API 服务器,以集成到应用程序中。
- 所需组件
- 多租户和资源隔离 (Keystone): 利用用户身份验证和项目分离,以确保虽然多个租户共享基础设施,但他们无法访问或影响彼此的资源。
- 可靠的虚拟机 (VM) 配置 (Nova): 为了快速创建和提供具有各种大小的 CPU、内存和 GPU 的 VM。
- 块和对象存储 (Cinder/Swift): 为了为训练数据集和训练好的模型工件提供稳定的存储。
- 基本网络 (Neutron): 为了配置用于外部访问和 interservice 通信的虚拟网络环境。
- 容器支持 (Magnum): 为了配置 Kubernetes 集群,以便更灵活地管理模型服务环境。
场景 2:GPU 即服务 (GPUaaS) 平台
重要性: GPU 功能强大但极其昂贵,单个用户通常无法充分利用它。 此场景就像 GPU 的公寓楼:与其每个人购买整栋房子(物理 GPU),不如租用公寓(虚拟 GPU 切片)。 这种方法允许许多用户(租户)共享昂贵的硬件,安全高效地仅为他们需要的资源付费。 这对于使人工智能在整个组织中具有经济性和可扩展性至关重要。
- 描述: 用户通过云门户或 API 分配具有特定要求的 GPU(vGPU、MIG)给他们的 VM。 管理员监控资源使用情况、应用计费策略并确保每个租户的工作完全与其他租户隔离。
- 所需组件
- 多租户和资源隔离 (Keystone): 提供用户身份验证和项目分离,以确保虽然多个租户共享基础设施,但他们无法访问或影响彼此的资源。
- GPU 虚拟化 (vGPU/MIG): 将单个物理 GPU 分割成多个逻辑 vGPU 或 MIG 实例,可以同时分配给多个用户。
- 智能 GPU 编排和调度 (Cyborg/Placement): 处理多样化和动态的调度请求(例如,特定的 GPU 型号、内存要求)。 它智能地将工作负载分配到最合适的 GPU,甚至可以重新安排它们以合并工作负载,从而最大限度地利用每个节点的 GPU 并最大限度地减少资源碎片。
- PCI 直通: 将物理 GPU 直接分配给 VM,以保证最大性能。
- 使用计量和计费 (Ceilometer/CloudKitty): 准确测量 GPU 资源使用情况并与计费系统集成。
- 自助服务门户 (Horizon): 提供基于 Web 的仪表板,供用户自行请求和管理 GPU 资源。
场景 3:完全自动化的 MLOps(机器学习运维)平台
重要性: 生产中的 AI 模型不是“设置好就忘掉”的工具。 随着新数据的出现,它可能会过时。 MLOps 就像为 AI 创建一个自动化的工业装配线:而不是开发人员手动构建、测试和部署每次更新,该系统会自动执行整个过程。 它确保 AI 服务始终是最新的、可靠的并且可以快速安全地改进,从而从手动工艺转变为可扩展的专业运营。
- 描述: 当代码更改时,模型会自动测试、重新训练并在性能验证后部署到生产环境。 如果检测到模型性能下降,它会自动生成并发送警报,并触发重新训练管道。
- 所需组件
- 多租户和资源隔离 (Keystone): 利用用户身份验证和项目分离,以确保虽然多个租户共享基础设施,但他们无法访问或影响彼此的资源。
- CI/CD 管道集成: 与 Jenkins 或 GitLab CI 等工具集成,以在代码更改时执行自动化工作流程。
- 工作流程编排 (Kubeflow/Airflow): 在 OpenStack 构建的 Kubernetes 集群上管理复杂的训练和部署管道。
- 模型和数据版本控制 (MLflow/DVC): 系统地跟踪模型、数据和实验结果,以确保可重复性。
- 强大的网络和存储: 与 Neutron、Cinder 和 Ceph 紧密集成,以快速处理大规模数据。
场景 4:用于大规模人工智能研究的高性能计算 (HPC) 集群
重要性: 一些 AI 模型,例如 ChatGPT 背后的模型,非常庞大。 在单台计算机上训练它们可能需要数年时间。 此场景是关于构建专门用于 AI 的超级计算机。 它将数百或数千个 GPU 与超快速连接连接起来,使它们能够作为一个巨大的系统运行。 这种 HPC 方法对于前沿研究、训练基础模型以及突破人工智能的界限至关重要。
- 描述: 研究人员使用并行计算框架,例如 MPI,在多个节点上分布式训练大型模型。 基础设施经过优化,以最大限度地减少 GPU 之间的通信延迟并快速处理大型数据集。
- 所需组件
- 高速网络 (InfiniBand/RDMA): 利用 SR-IOV 等技术来最大限度地减少 GPU 之间的通信瓶颈。
- 高性能并行文件系统 (Lustre/BeeGFS): 支持对大型训练数据的快速、并行访问。
- 裸机配置 (Ironic): 消除虚拟化开销并最大限度地提高硬件性能,以减少训练时间。
- GPU 拓扑感知调度: 考虑物理硬件架构,例如 NUMA 节点和 NVLink 连接,以将 VM 或容器放置在最佳性能的位置。
场景 5:AIoT 和边缘计算
重要性: 将所有来自智能设备(例如工厂摄像头或自动驾驶汽车)的数据发送到中央云通常在必须在几分之一秒内做出决策时太慢且太昂贵。 此场景是关于将较小、更高效的 AI 系统直接放置在设备本身(在“边缘”)上。 中央 OpenStack 云充当“总部”,管理这些分布式系统、发送软件更新并集中收集关键结果。 这对于实时应用(例如检测快速移动装配线上的制造缺陷)至关重要。
- 描述: 从边缘设备收集的数据在本地处理,而中央云根据此数据重新训练模型并将更新的模型部署回边缘。
- 所需组件
- 分布式/轻量级架构(例如,StarlingX): 有效管理中央数据中心和多个边缘站点。
- 支持专门的边缘加速器: 支持和管理低功耗边缘设备和加速器,例如 NVIDIA Jetson 或 Google Coral。
- 轻量级容器环境 (K3s/MicroK8s): 支持针对资源受限的边缘环境优化的容器编排。
- 中央到边缘的安全性和管理: 提供中央云和边缘设备之间安全通信和远程部署模型和软件的功能。
基础设施需求
加速计算
Cyborg
OpenStack Cyborg 解决了这一差距,提供了一个专门的加速器管理服务,该服务与 OpenStack 生态系统无缝集成,能够高效地在异构基础设施上部署人工智能工作负载。
Cyborg 在人工智能中的作用
- 发现和清单: 自动检测计算节点上可用的 GPU、FPGA、NPU 和 SmartNIC。
- 调度和放置: 与 Placement 服务集成,以确保人工智能工作负载被调度到具有所需加速器的节点上。
- 生命周期管理: 提供 API 以在实例创建和删除期间分配、绑定和释放加速器。
- 供应商无关: 支持 NVIDIA、AMD、Intel、Xilinx 等的插拔驱动程序模型。
通过与 Nova 和 Placement 无缝集成,Cyborg 确保人工智能工作负载——无论是训练大型深度学习模型还是运行低延迟推理——都能在正确的时间获得正确的加速器。 这使企业能够降低成本、最大限度地提高性能和扩展人工智能采用跨混合和多云环境。
Nova
OpenStack Nova 是 OpenStack 云计算平台的主要计算服务。它的使命是成为可扩展、按需的组件,用于配置和管理虚拟机、容器和裸机服务器,本质上为云的基础设施提供“引擎”。Nova 通过提供运行 AI 工作负载所需的基础计算资源来支持 AI 用例。它允许用户快速配置和扩展或缩减训练复杂的机器学习模型、大规模运行推理以及管理整个 AI 开发生命周期所需的虚拟服务器。
作为 OpenStack 的计算服务,Nova 自 Icehouse 版本发布以来就 支持 GPU 直通。这种长期存在的特性允许将物理 GPU 直接分配给虚拟机,提供对要求苛刻的 AI 工作负载至关重要的类似裸机的性能。
Nova 随后支持 NVIDIA GRID(以及后来的 NVIDIA AI Enterprise)虚拟 GPU (vGPU) 自 Queens 版本发布以来。在这种模式下,单个物理 GPU 可以共享给多个虚拟机,虚拟化 GPU 内存和计算单元等资源。这允许在多租户环境中实现更高的 GPU 利用率和成本效益。
GPU 支持
PCI 直通
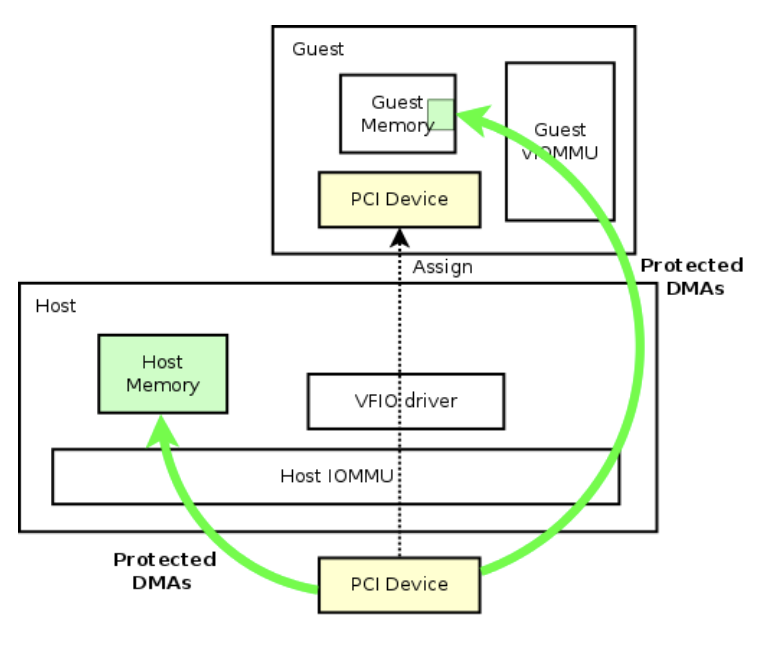 PCI 直通是 OpenStack 中原生支持的一项功能,它通过允许将物理 GPU 直接分配给虚拟机,提供了一个引人注目的解决方案。利用 Intel VT-d 或 AMD-Vi 和输入/输出内存管理单元 (IOMMU) 技术,PCI 直通能够安全且隔离地访问虚拟机内的 PCI 设备。这种方法绕过虚拟化层以提供类似裸机的性能,使其成为对延迟敏感或需要大量 GPU 资源的应用程序的理想选择,例如 AI 训练、推理和高性能计算 (HPC) 工作负载。
PCI 直通是 OpenStack 中原生支持的一项功能,它通过允许将物理 GPU 直接分配给虚拟机,提供了一个引人注目的解决方案。利用 Intel VT-d 或 AMD-Vi 和输入/输出内存管理单元 (IOMMU) 技术,PCI 直通能够安全且隔离地访问虚拟机内的 PCI 设备。这种方法绕过虚拟化层以提供类似裸机的性能,使其成为对延迟敏感或需要大量 GPU 资源的应用程序的理想选择,例如 AI 训练、推理和高性能计算 (HPC) 工作负载。
PCI 直通在 OpenStack 中的一个关键优势在于其简单性和广泛的兼容性。操作员可以使用基于 flavor 的配置和额外的规范轻松地将 GPU 暴露给虚拟机,从而允许为每个实例分配单个或多个 GPU。这种模式尤其适用于具有异构 GPU 硬件的集群,包括消费级设备,如 NVIDIA RTX、GTX 或 AMD 卡,这些设备通常不受供应商授权的虚拟 GPU (vGPU) 软件支持。通过规避专有解决方案的限制,PCI 直通提供了一种供应商中立且无需许可的方法来提供 GPU 加速。它在学术界、研究领域和边缘环境中尤其有价值,在这些环境中,成本效益和灵活性至关重要。
然而,PCI 直通模型也引入了一些操作方面的考虑因素。通过 PCI 直通分配的每个 GPU 专用于单个虚拟机,这限制了资源共享和动态工作负载调度。此外,管理具有多个 GPU 供应商和模型的庞大 OpenStack 集群可能会变得复杂,尤其是在处理 IOMMU 组隔离、PCIe 拓扑约束或设备之间重置和热插拔功能的不一致支持时。尽管存在这些挑战,PCI 直通仍然是开放基础设施上高性能 AI 工作负载的关键推动因素,它在保持云的可扩展性和自动化能力的同时,提供了裸机的性能优势。
一些硬件供应商默认将所有 GPU 卡连接到裸机配置中的单个 NUMA 节点。虽然这种设置可以在原生环境中提高 CPU 和内存访问效率,但对于虚拟化而言,它不是最优的。在虚拟化环境中,此配置会在 CPU、内存和 GPU 之间引入跨 NUMA 访问,这会增加延迟并降低 GPU 性能,因为数据平面通信效率低下。更有效的虚拟化 NUMA 配置是将 GPU 均匀地分布在 NUMA 节点上。这可以更好地将虚拟机与底层硬件资源对齐。 有关 Nova PCI 直通配置的最佳实践,有一些 教程可以提供帮助。
硬件 GPU NUMA 配置文件
标准服务器上通常存在两种常见的 GPU PCIe/NUMA 拓扑,您可以使用 lstopo 验证您拥有的拓扑。每种拓扑都偏爱不同的工作负载;选择错误的拓扑可能会降低性能并增加端到端延迟。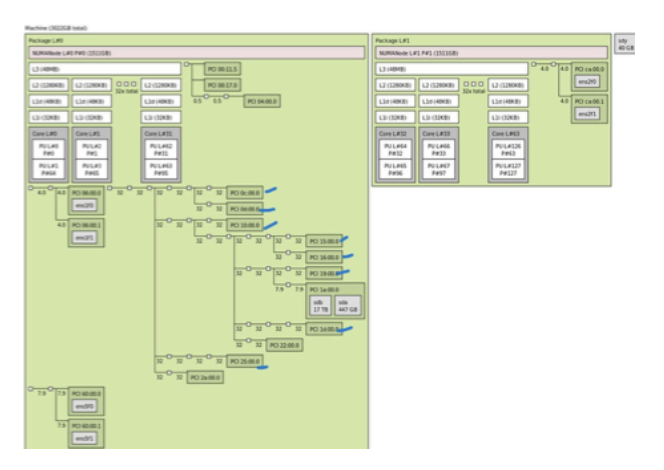 配置文件 A — GPU 集中在一个 NUMA 节点上:
配置文件 A — GPU 集中在一个 NUMA 节点上:
- 最适合保持 CPU 内存访问到该 socket 的本地的裸机作业(例如,单租户训练)。
- 对于虚拟化或多 socket CPU 使用而言,存在风险,因为跨 NUMA 内存流量到 GPU 会增加延迟。
配置文件 B — GPU 分布在 NUMA 节点上
- 更适合虚拟化和多 VM 场景,您可以将每个 VM 的 vCPU 和内存与 GPU 的 NUMA 节点对齐(NUMA 亲和性)。
- 减少跨 socket 跳跃并提高延迟一致性。
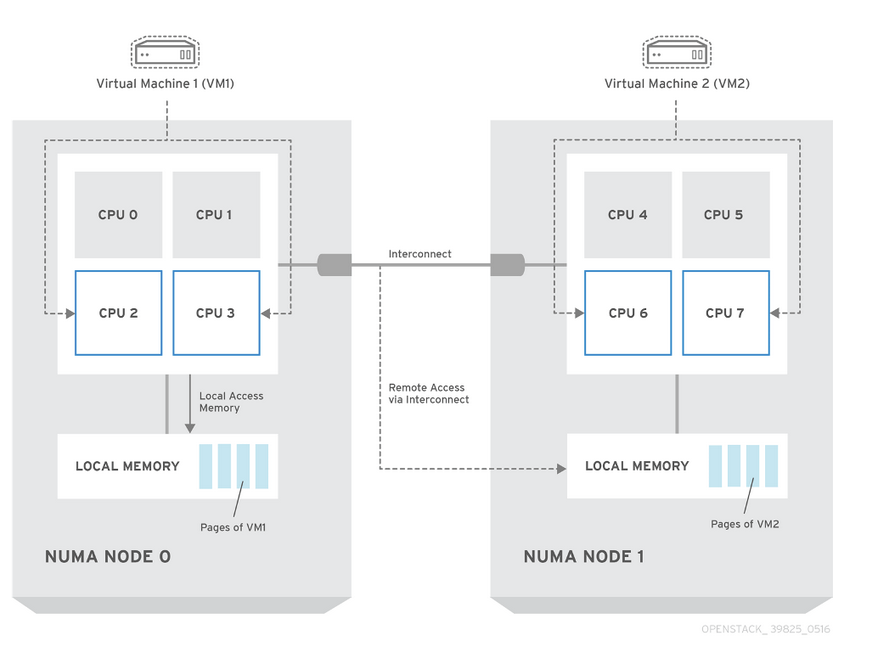
GPU-CPU 亲和性配置。GPU–CPU 亲和性配置:将 vCPU 与位于同一 NUMA 节点上的 GPU 对齐,可以减少 GPU 在内存、CPU 和 GPU 之间传输数据时的延迟,从而提高 VM 性能。
CPU Pinning 技术:通过将专用 CPU 核心分配给每个实例,提高 GPU VM 的性能。
NVIDIA vGPU 和 MIG
NVIDIA 的 vGPU 和多实例 GPU (MIG) 具有相同的目的,即在多个消费者之间共享 GPU 资源,但它们是根本不同的方法。NVIDIA 在十多年前推出了 vGPU,而 MIG 是 2020 年与 NVIDIA Ampere 架构一起首次推出的。让我们看看这些技术如何比较。
vGPU 是一种软件驱动的虚拟化,允许将内存和 GPU 功能以小数部分分配给客户操作系统。vGPU 允许时间共享 GPU,类似于超visor 允许通过 vCPU 核心在不同的客户 VM 之间共享 CPU 的方式。
另一方面,MIG 是一种基于硬件的分割机制,它将 GPU 分割成几个隔离的、独立的 GPU 实例,这些实例具有专用的计算核心、内存和缓存。这两种方法之间的根本差异具有实际意义。
MIG 提供确定性的、无噪声邻居隔离和可预测的吞吐量,因为每个 MIG 实例都映射到固定的硬件资源。它非常适合延迟敏感的推理、吞吐量隔离或密集型工作负载,这些工作负载是在当今专为 AI 和 ML 设计的多租户云环境中遇到的。
相反,vGPU 由于共享相同的硬件而容易受到噪声邻居问题的影响。因此,它非常适合工作负载资源需求多变的场景,例如虚拟桌面基础设施 (VDI) 和通用工作负载,例如 3D 或视频渲染。
示意性地,vGPU 和 MIG 之间的差异如图所示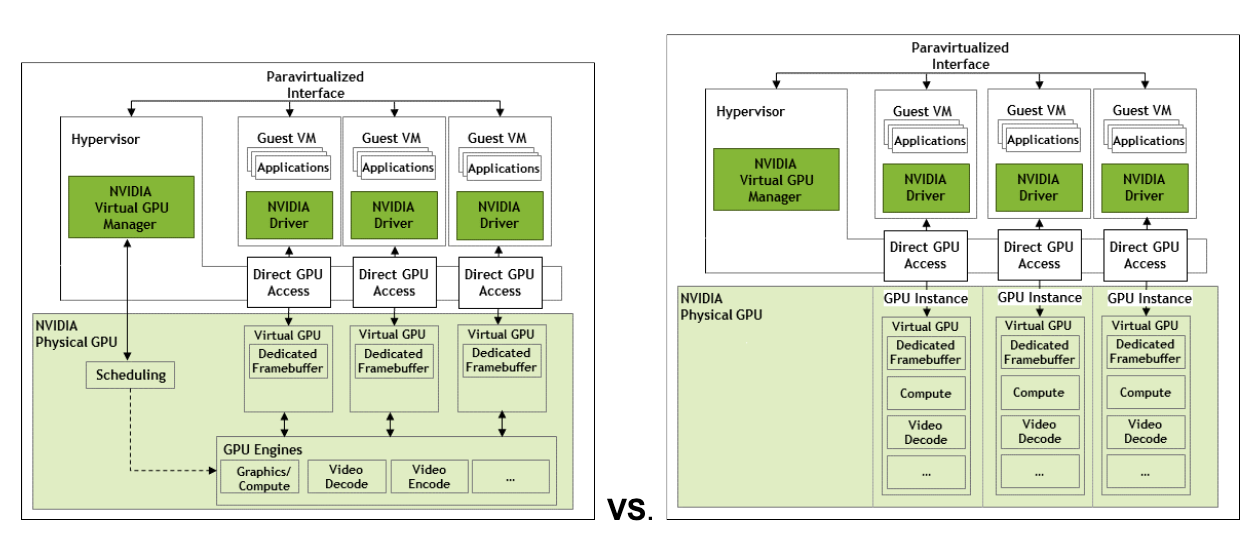
值得注意的是,MIG 受到高端数据中心和专业 GPU 模型(例如 NVIDIA A30/A100/H100/H200 和 RTX Pro 6000)的支持,而 vGPU 支持则涵盖更广泛的 NVIDIA GPU 模型。每个 GPU 上可用 MIG 实例的数量也因 GPU 模型而异,并且限制为每个卡最多七个。这意味着最多七个用户可以共享一个 MIG GPU。使用 vGPU,消费者的数量由配置文件决定,这些配置文件将可用的 GPU 内存划分为固定块,这些块可以小至 1GB 或大至整个 VRAM,这意味着 vGPU 潜在地允许更多用户共享一个 GPU。有关 vGPU 共享的影响,请参阅 NVIDIA 文档。下表总结了 vGPU 与 MIG 与 GPU 直通方法及其用例。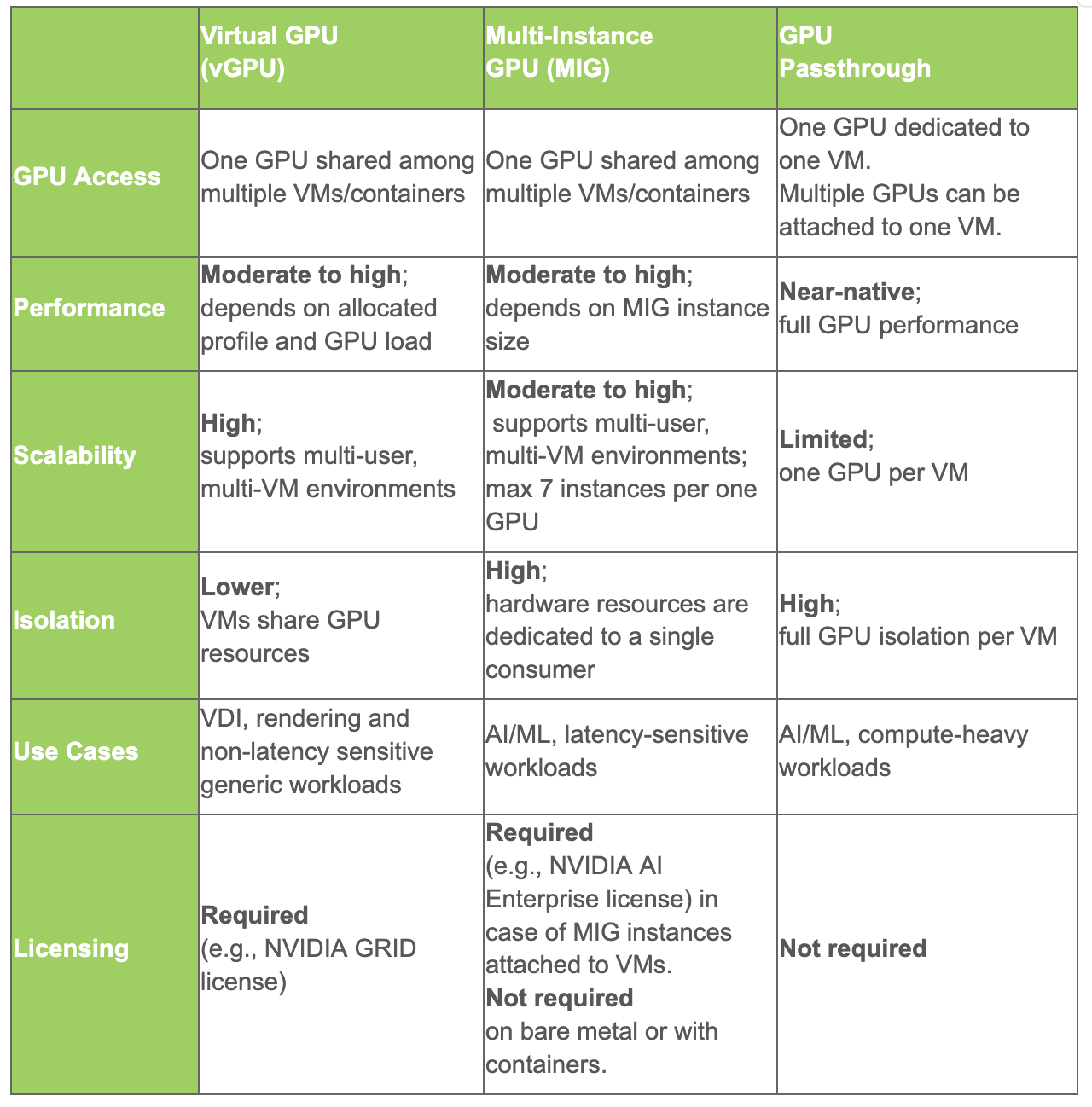
AMD SR-IOV
AMD 的 MxGPU 技术代表一种基于硬件的 GPU 虚拟化方法,使单个物理 GPU 能够被分割并在多个虚拟机之间共享。这项技术的核心是单根 I/O 虚拟化 (SR-IOV),这是 PCI 特别兴趣组 (PCI-SIG) 开发的标准,以及 AMD PF 主机驱动程序(也称为 GIM(GPU-IOV 模块)驱动程序)的关键作用,该驱动程序最近在 GitHub 上开源。MxGPU 使用 SR-IOV 从单个“物理功能” (PF) 创建“虚拟功能” (VF),然后可以在 VM 中安全地虚拟化该 VF。在多 GPU 系统的情况下,它允许使用多个互连 GPU 和 xGMI 桥接在一个 VM 中。
GIM 驱动程序是主机端内核驱动程序,它协调整个 MxGPU 虚拟化过程。它充当超visor 和物理 GPU 之间的中间体,管理 VF 的创建和配置。
在客户机端,有一个 VF 驱动程序,它是安装在 VM 操作系统内的 ROCm 软件堆栈的组件。此驱动程序使客户机能够识别、与分配的虚拟 GPU 资源通信并有效地使用它们。
高速 GPU 互连
- NVLink:NVIDIA NVLink 是一种高带宽、低延迟的互连,允许 GPU 之间以及与 CPU 之间直接通信。通过绕过 PCIe 总线,NVLink 提供了更高的带宽和更低的延迟,从而加快了 AI 训练和推理的数据传输。
- Infinity Fabric:AMD 的 Infinity Fabric 是一种可扩展的互连架构,它连接 CPU、GPU 和其他组件。它提供高吞吐量和低延迟,支持异构计算环境中的高效通信。对于 AI 工作负载,Infinity Fabric 有助于优化多 GPU 配置,减少大规模训练期间的瓶颈。
存储
AI 工作负载带来了复杂的存储挑战:海量数据集、高吞吐量需求和容错架构。Ceph 是一种开源、软件定义的存储系统,提供统一、可扩展且容错的存储解决方案,可以与 OpenStack 无缝集成,使其成为以 AI 为中心的云部署的理想选择。
AI 工作负载通常跨越三个阶段。数据准备阶段需要高吞吐量的顺序读取,并支持各种数据类型,包括结构化数据集、多媒体文件和传感器数据。模型训练阶段需要持续的高带宽存储来持续馈送 GPU 加速器并处理随机数据访问模式,而检查点功能对于保存中间模型状态至关重要。推理服务阶段依赖于对训练模型的低延迟访问和实时数据处理,需要存储系统在处理并发请求时不会降低性能。
可扩展性、性能和高效的数据管理对于 AI 工作负载至关重要。存储系统必须处理大型数据集,同时随着基础设施扩展保持线性性能。
Manila
在研究行业中,通常使用共享文件系统来分发工具、库和数据集,以便在计算实体上进行进一步处理;存储和共享结果;或者,更一般地说,跨不同项目(即 OpenStack 租户)管理辅助文件。
对于需要共享、基于文件的访问的用例,传统的块或对象存储选项可能不是理想的选择。相反,Manila 项目在提供网络文件系统作为一项服务 (NFSaaS) 方面拥有强大的记录,特别是——但并非仅限于——与 Ceph 作为 NFS 共享的后端存储一起使用时。
Manila 项目允许用户在租户实例中创建、导出和挂载文件共享,甚至在多个租户之间共享它们,类似于 AWS Elastic File System (EFS) 等云服务。
功能包括
- 基于角色的访问控制
- 访问控制列表
- 分层
- 配额管理
- 快照创建
- 支持各种后端,从传统的存储供应商(例如 NetApp、Pure Storage)到开源解决方案,例如 CephFS
为了充分释放存储层上的 Ceph 的功能,可以启用 CephFS 以提供基于文件的访问(除了前面提到的块和对象类型),从而允许 Manila 将其用作后端。
通常有两种将 Manila 项目与 CephFS 集成的选项,并且选择取决于特定的用例、安全要求和管理偏好。
- CephFS 原生驱动程序:实例直接使用 CephFS 客户端和协议连接到公共 Ceph 网络。
- CephFS-NFS 驱动程序:Manila 使用 NFS-Ganesha 服务作为租户网络和 Ceph 存储网络之间的代理。这增强了隔离性,但增加了复杂性。客户端通过 NFSv4 协议访问共享。
- 总而言之,Manila 可以成为本文中描述的许多用例的一个有趣的替代方案。
Ceph
Ceph 提供统一的存储模型,将块、对象和文件存储整合到一个系统中,从而降低了复杂性,同时支持各种 AI 数据类型。它基于 RADOS 基础构建,确保容错性和可扩展性,使其成为现代 AI 基础设施的理想选择。其高性能接口包括:
- RBD 用于具有快照和精简配置的持久卷
- RGW 用于与 S3 兼容的对象存储,适用于训练数据集和工件,
- CephFS 用于协作工作流程和分布式训练。
Ceph 与 OpenStack 深度集成,简化了 AI 部署。Cinder 和 Nova 实现了高效的 VM 存储和 AI 管道的持久卷。Glance 和 Swift 促进了预配置 AI 环境的快速部署和可扩展的对象存储。Keystone 集成确保了安全的、多租户环境,从而可以有效地隔离 AI 项目。
为了获得最佳的 AI 性能,Ceph 的 BlueStore 引擎提供更高的 IOPS 和更低的延迟,这对于训练和推理工作负载至关重要。擦除编码在存储效率和性能之间提供平衡,而 NVMe SSD 和高速网络对于满足基于 GPU 的工作负载的高吞吐量需求至关重要。
Ceph的灵活性、开源基础和活跃的开发社区使其非常适合不断发展的AI技术,例如GPU Direct Storage和容器化的AI工作流程。采用Ceph的组织可以获得供应商独立性、可扩展性和下一代AI应用程序所需的性能。
网络
人工智能通常被描述为一种以数据为中心的研究领域,而大量数据的有效移动也带来网络挑战。 网络性能对于确保AI工作负载高效运行至关重要。
开放基础设施的每个方面都为系统架构师提供了需要考虑的选择,而网络是一个正确决策可以产生最大影响的领域。
网络可用的各种选项构成了一个从便利性到性能的连续体。
- OpenStack中的标准半虚拟化网络可以通过在hypervisor虚拟化引擎中启用多队列等选项来优化聚合吞吐量。
- OpenStack通过SR-IOV和Open vSwitch硬件卸载等技术支持高性能以太网网络,通过在硬件中实现网络功能来创建更薄的虚拟化层。
- 除了以太网网络,OpenStack还支持InfiniBand网络的集成,包括通过InfiniBand分区密钥实现多租户网络隔离。
- 对于最高的性能需求,OpenStack可以配置裸机计算基础设施,完全消除计算虚拟化开销。
优化半虚拟化网络
通常可以在不依赖硬件解决方案的情况下提高网络性能。
- 增加最大传输单元 (MTU) 大小,例如 9,000 字节的“巨型帧”。 半虚拟化软件网络通常受限于数据包处理速率。更大的以太网帧可以减少给定数量数据的数据包处理速率。
- 在hypervisor网络堆栈中启用VIF多队列。 在高度并发的网络连接中,可以通过将多个hypervisor CPU核心专门用于网络数据路径的数据包处理来增加聚合带宽。 VIF多队列通过镜像属性 hw_vif_multiqueue_enabled 启用(了解更多)。
- 通过使用提供商VLAN来简化数据路径,以实现对外部存储的高速访问。 在某些情况下,内部网络也可以配置为具有精简的功能,例如禁用端口安全,以减少开销。
硬件卸载以太网
OpenStack网络可以利用硬件卸载以太网的强大功能。
多年来,单根IO虚拟化 (SR-IOV) 一直为虚拟机提供访问高性能网络的功能。 传统的SR-IOV支持基本功能,例如多租户VLAN网络隔离,但通常不支持重要的增强功能,例如端口安全、容错能力或实时迁移。
高端网络适配器的最新创新现在允许
- 来自成对物理接口的单个SR-IOV端口,透明地为虚拟机提供冗余网络连接,能够以主动-主动方式使用两个链路。
- 支持具有高性能网络连接的虚拟机的实时迁移,允许工作负载迁移到另一个hypervisor(例如,当需要hypervisor维护时)。
- 通过以太网的RDMA (RoCE) 是一种源自高性能计算 (HPC) 的网络协议。 RoCE是用于数据传输和通信的各种协议的基础,包括用于分布式AI用例和高性能存储。 RoCE在以太网网络中实现了本机InfiniBand协议,但与InfiniBand本身相比,引入了少量性能开销。
- 网络流规则的硬件卸载。 在传统的OpenStack网络中,流规则是配置核心网络组件(例如Open vSwitch)的底层机制。 流规则定义了广泛的虚拟网络功能,包括端口安全、浮动IP和负载均衡器。
只有在使用配备此功能的的高端网络接口时,才能使用这些功能。
OpenStack中的InfiniBand
InfiniBand网络经常包含在高端AI基础设施中,以实现最大性能。 InfiniBand在几个关键方面与以太网不同。
- InfiniBand可以支持IPv4寻址和路由,但其底层架构与以太网有很大不同。 配置由监督控制过程集中管理,该过程称为子网管理器。(注意:InfiniBand术语中的子网与基于以太网的网络中的概念不同。)
- InfiniBand使用分区来实现逻辑网络分离,类似于基于以太网的VLAN。 多租户网络隔离使用InfiniBand分区密钥实现。
- 子网管理器是一种可以与OpenStack控制平面服务一起部署的软件服务。 OpenSM是一个免费且开源的子网管理器,提供基本功能。 NVIDIA维护着OpenSM的一个分支,该分支支持虚拟化和SR-IOV功能。 NVIDIA Unified Fabric Manager (UFM) 是一个替代的商业解决方案,具有企业级功能。 动态支持多租户网络隔离需要UFM中实现的功能。
- OpenStack通过networking-mlnx Neutron驱动程序支持InfiniBand网络。 从OpenStack的角度来看,它扩展了Nova和Neutron,以完全支持InfiniBand虚拟接口 (VIF)。
更详细、更实际地说,OpenStack中的InfiniBand
- 允许在OpenStack中定义基于InfiniBand的物理网络。
- 处理VFs的GUID分配。
- 将GUID从Neutron映射到MAC地址。
- 为IPoIB提供DHCP服务器。
- 将VLAN提供商段映射到符合InfiniBand的partition定义。
- 将适当的GUID分配给正确的partition。
- 允许将基于IB的VIF附加到虚拟机。
在云计算中,经常存在忽略InfiniBand功能的假设,在实施启用了InfiniBand的云基础设施时必须考虑这些假设。
- 云软件镜像的默认构建甚至缺少InfiniBand的基本驱动程序。
- 在某些Linux发行版中,cloud-init不支持InfiniBand网络设备。
- 在许多情况下,期望实例具有主以太网接口。 纯InfiniBand系统可能会测试许多关于Linux网络的假设。
- 建议使用ConfigDrive提供cloud-init元数据。
一旦部署并配置了InfiniBand,它将为虚拟化环境中的AI工作负载提供最大性能。
裸机基础设施的网络
为了满足性能的最终要求,OpenStack支持裸机计算和网络。 OpenStack Ironic将物理硬件表示为虚拟机,并将物理网络端口表示为虚拟接口。 许多软件定义基础设施的抽象在裸机环境中都有等效物。
- 可以使用networking-generic-switch Neutron驱动程序实现以太网VLAN网络的租户网络隔离,该驱动程序支持各种流行的网络交换机供应商。
- 该驱动程序还可以支持绑定网络端口和VLAN标记的trunk接口。
- InfiniBand网络与虚拟化计算一起支持裸机计算,使用相同的networking-mlnx Neutron驱动程序。
裸机网络不如其虚拟对应网络灵活,并且不能总是提供相同的功能。 例如,端口安全不容易在裸机环境中实现。 因此,裸机计算资源通常与直接外部访问隔离,并与虚拟化计算基础设施配对,作为控制对裸机计算的访问的网关。
Neutron
人工智能 (AI) 工作负载需要大量的计算资源,通常分布在大型集群中。因此,连接这些服务器的网络对要求非常严格。为了满足这些要求,网络必须提供高带宽、低延迟和无损数据传输。
OpenStack网络服务Neutron通过几个关键功能解决了这些挑战
- 服务质量 (QoS): 配置策略,以保证网络端口的带宽和/或每秒数据包数 (PPS)。Neutron与Placement API服务协同工作,以强制执行这些资源保证,确保虚拟机获得其所需的稳定网络性能。
- SR-IOV集成: 允许将物理网络设备功能直接附加到虚拟机。这种方法绕过虚拟交换机,为虚拟机提供本机、硬件级别的网络性能,并显著降低延迟和CPU开销。
- DPDK加速的虚拟交换: 利用networking-dpdk等插件来利用数据平面开发工具包 (DPDK) 框架。这可以提供高性能的、用户空间数据包处理,从而大大加速参与网络密集型任务的虚拟机的吞吐量。
- 无状态安全组: 为数据包过滤提供性能增强的替代方案。在网络安全至关重要但状态连接跟踪的开销不可取的场景中,无状态安全组可以通过简化防火墙规则处理来显著提高网络吞吐量。
指标收集
指标收集注意事项
GPU工作负载引入了新的监控要求,除了标准的平台指标之外。供应商支持的代理(例如NVIDIA的dcgm-exporter)报告GPU性能、功耗和利用率的详细信息。管理员必须决定要监控哪些边界,以及所选工具是否支持预期的模型。
使用完全设备PCI直通时,供应商代理无法在平台级别运行,因为GPU完全分配给来宾虚拟机。在这种情况下,代理必须在虚拟机内部运行。相反,当GPU使用vGPU、MIG或SR-IOV进行虚拟化时,管理员可以根据需要选择在计算节点或虚拟机内部运行监控代理。
人工智能工作负载的服务模型
对于基于OpenStack的私有云,新兴的挑战之一是在平台内将大型语言模型 (LLM) 推理作为一流服务提供。虽然OpenStack长期以来为传统工作负载提供了虚拟化、存储和网络基本组件,但AI推理引入了一组新的要求:细粒度的GPU内存管理、低延迟请求服务以及高效利用高成本加速器资源。
这就是vLLM变得非常重要的原因。通过充当高性能推理运行时,可以部署在OpenStack的计算和加速器基础设施之上,vLLM将原始GPU容量转换为优化的服务层,使运营商能够以云原生效率运行推理工作负载。
vLLM的核心是PagedAttention,这是一种直接解决基于transformer的模型中固有的GPU内存效率低下问题的创新。OpenStack部署中的传统推理服务器通常依赖于静态KV缓存分配,这会导致内存碎片和较差的GPU利用率,尤其是在多租户环境中。PagedAttention为KV缓存引入了虚拟内存抽象,将其组织成固定大小的页面,这些页面可以按需分配、回收和重新映射。这种方法允许多个租户,每个租户运行具有不同序列长度的请求,共享GPU资源而不浪费内存。对于OpenStack运营商而言,这意味着更高的整合比率(每个GPU更多的并发请求)、更好的租户公平性和AI服务的较低TCO。
vLLM的另一个核心优势是连续批处理,这与OpenStack环境中面临的多租户调度挑战直接相关。传统的静态批处理迫使工作负载等待足够多的请求到达以形成批处理,导致GPU利用率不足和不可预测的延迟。vLLM的连续批处理引擎动态地将新请求合并到正在运行的执行图中,在高度可变的租户流量模式下实现接近最佳的GPU饱和度。这确保了OpenStack部署可以处理各种推理工作负载——从突发实时聊天机器人请求到大型批处理分析作业——同时保持可预测的延迟。
从操作角度来看,vLLM提供了一个与OpenAI兼容的API,可以作为OpenStack服务端点公开,使租户可以通过熟悉的接口轻松使用LLM推理。它开箱即用地支持Hugging Face模型和LoRA微调变体,并使用分布式推理和张量并行性在OpenStack集群上水平扩展。结合OpenStack的编排工具,运营商可以提供具有弹性、多租户感知能力和受企业级SLA支持的LLM即服务产品。
vLLM使OpenStack能够扩展到AI推理即服务,弥合GPU硬件可用性和生产级模型服务之间的差距。它的创新——PagedAttention用于内存效率、连续批处理用于调度效率以及与开发人员期望一致的API表面——使其成为寻求将其云平台现代化以适应AI时代的OpenStack运营商的理想选择。
vLLM 和 OpenAI 兼容的 API
对于模型服务平台,vLLM最实用的优势之一是它对与OpenAI兼容的API层的支持。此功能允许组织通过广泛采用的行业标准API协议公开LLM推理,而无需开发人员或应用程序更改现有的集成逻辑。通过镜像OpenAI API模式,用于/completions、/chat/completions和/embeddings等端点,vLLM可以实现无缝采用,适用于已经构建在商业LLM提供商之上的应用程序。
从服务架构的角度来看,这种兼容性提供了两个显著的好处
- 较低的迁移障碍。企业可以将工作负载从专有SaaS环境迁移到私有或混合云。以前锁定在OpenAI托管API中的应用程序可以仅进行最少的配置更改,将流量重定向到企业控制的环境(例如OpenStack集群)内的vLLM支持的端点。
- 多云灵活性。相同的应用程序可以根据成本、延迟或合规性要求,针对外部API或本地vLLM部署运行。
从技术上讲,vLLM 的 API 层与其运行时优化紧密集成,例如 PagedAttention 和连续批处理。这意味着到达 /chat/completions 端点的请求会自动调度到连续批处理引擎中,即使在峰值或异构工作负载下也能确保高 GPU 利用率。开箱即用地支持令牌流,使实时应用程序(如聊天机器人、副驾驶或代理框架)能够增量地消耗输出,而无需自定义管道。此外,vLLM 支持在相同的 API 表面下使用微调模型和适配器(例如,基于 LoRA 的变体),使运营商能够灵活地向最终用户公开基础模型和领域专用版本,而不会出现 API 碎片化。
从运营角度来看,与 OpenAI 兼容的 API 可实现服务标准化。无论租户是使用商业 API 还是私有 vLLM 端点,都可以一致地应用监控、日志记录和配额执行。对于基于 OpenStack 或 Kubernetes 的环境,此 API 可以通过标准服务组件(如 Ingress 控制器)进行前端处理,从而实现水平扩展并支持企业级 SLA。
vLLM 中的与 OpenAI 兼容的 API 弥合了推理优化和开发人员采用之间的差距,确保组织可以在自己的基础设施中部署 LLM 服务,而不会牺牲兼容性或性能。它将 vLLM 从一个研究优化的运行时转变为一个生产就绪、开发人员友好的 LLM-as-a-Service 平台。
混合分布式边缘人工智能云
人工智能的未来需要超越集中式云。实时应用程序,例如在自主系统或智能工厂中,需要在数据源附近以微秒级的速度做出决策。这导致了混合分布式边缘人工智能云模型,该模型将中央 OpenStack 云与较小、高速边缘服务器的星系合并。
这种架构利用更靠近数据的较小服务器网络来即时处理反应性工作数据 (RWD)。中央 OpenStack 云是“大脑”,训练大型基础模型并推送更新。边缘服务器是“肢体”,执行低延迟推理。
核心组件 & OpenStack 集成
- 边缘微服务器:小型、资源高效的服务器处理本地推理。OpenStack 的 Nova 和 Cyborg 可以配置轻量级容器并管理这些节点上的专用边缘加速器(如 NVIDIA Jetson)。此外,边缘的微服务器还可以降低较小语言模型中的幻觉率。随着这种降低,边缘是拥有小型、目的驱动的代理的理想场所,可以在不依赖中央服务器的情况下做出可靠的近实时决策。一个例子是制造用例,较低的延迟会导致车间地板上更可靠的近实时决策。边缘的微服务器使车间地板上的轻量级代理能够处理监控和优化等任务,而无需联系中央服务器进行决策。
- 微秒级连接:超低延迟网络至关重要。Neutron 可以针对中央云和边缘节点之间的安全、直接通信进行优化,绕过传统的网络跳跃。
- 分布式存储:与其将所有数据发送到云端,Ceph 可以在边缘提供本地、有弹性的存储。只有少量汇总数据才会发送回中央云以进行模型改进。但是,在需要时,数据可以以 S3 格式传输,以便于集成和操作。此外,LF Edge 项目(如 EdgeLake)正在 OpenInfra 的基础层之上构建,以利用这三点来显着增强 AI 推理建模更新。
这种混合方法为商业、学术和运营目的解锁了实时智能,能够实现从工厂车间即时质量控制到科学数据立即分析的一切,同时利用 OpenStack 的灵活性和开源基础。
Keystone
在 AI 工作负载中,Keystone(身份和访问管理 (IAM) 服务)充当安全骨干,确保只有授权实体(人员、AI 代理或服务)才能以安全且可审计的方式访问特定资源。它是从数据到部署保护整个 AI 管道的基础。
保护数据和模型
AI 工作负载依赖于两种宝贵的资产:用于训练的数据和训练后的模型本身。
- 数据访问控制:训练数据可能非常敏感(例如,个人用户数据、财务记录)。Keystone 精确定义谁或什么可以读取、写入或删除此数据。这可以防止未经授权的访问和数据泄露。例如,AI 训练服务可能只能只读访问特定的数据存储桶,但无权删除它。
- 模型保护:训练后的 AI 模型是一项重要的知识产权。Keystone 可用于控制谁可以访问模型文件、部署模型或调用模型的 API 进行预测(推理)。这降低了模型被盗或篡改的风险
控制对基础设施的访问
AI 训练和推理通常需要强大的昂贵计算资源,如 GPU 和 TPU。
- 成本和资源管理:Keystone 确保只有授权的数据科学家或自动化服务才能启动或关闭这些昂贵的资源。这可以防止意外删除资源并帮助通过限制谁可以配置基础设施来控制云支出。
- 环境隔离:Keystone 用于在开发、测试和生产环境之间创建严格的边界。这确保了开发环境中的实验不会意外破坏实时生产模型。
启用安全自动化
现代 AI 工作流程高度自动化。AI 代理和 CI/CD 管道执行数据处理、模型训练和部署等任务,无需人工干预。
- 服务帐户和角色:Keystone 支持多种身份验证和授权概念。授权基于 RBAC 概念,并有一组定义允许的操作的角色。对于自动化流程,Keystone 提供了一种应用程序凭证的概念。这些是特殊的非人类身份,具有非常具体、细粒度的角色,这些角色可能与授予帐户的一般角色不同,并且可能是有限制的。目前正在进行支持临时服务帐户的工作。
- 示例:通过服务帐户运行的自动化训练脚本可能会被授予权限
- 从 data-bucket-A 读取数据。
- 在 GPU 集群上启动训练作业。
- 将最终模型写入 model-registry-B。
它将没有其他权限,这意味着它无法访问其他数据或服务,从而提供非常安全和有限的操作范围。
确保合规性和审计
对于许多行业来说,跟踪谁在何时访问什么是一种法律或法规要求(例如,GDPR、HIPAA)。
- 审计跟踪:Keystone 提供所有操作的全面日志,创建清晰的审计跟踪。如果发生数据泄露或模型行为异常,这些日志对于调查原因至关重要。
- 策略执行:Keystone 允许组织执行公司范围内的安全策略,确保整个 AI 工作负载遵守既定的合规标准。
Horizon
OpenStack Horizon 通过提供一个统一的 Web 仪表板来管理为 AI 提供支持的基础云基础设施,从而支持 AI 工作负载。它简化了配置和管理计算、存储和网络资源的过程,而无需复杂的命令行工具。
主要支持领域
- 计算能力:通过 Nova,Horizon 允许用户启动和管理具有必要硬件的 VM。这包括选择配置了 GPU 或其他硬件加速器的 VM 规格,这些加速器对于训练大型 AI 模型至关重要。
- 可扩展存储:AI 模型需要大量的存储空间。Horizon 提供了一个接口来配置用于此数据的不同类型的存储,包括
- 块存储 (Cinder):非常适合操作系统和需要单个实例快速直接访问的数据集。
- 对象存储 (Swift):用于可以被多个实例访问的大型非结构化数据集,例如大型训练图像集合。
- 网络管理:Horizon 简化了 AI 环境的网络配置。用户可以轻松创建私有网络以隔离其工作负载,管理外部访问的浮动 IP,并配置安全组以控制流量,从而确保安全且组织良好的环境。
- 可重复性:为了确保 AI 实验一致,开发人员可以创建预配置库的自定义镜像。Horizon 使得上传和使用这些镜像以快速启动用于测试或团队协作的相同环境变得容易。
- Resource 和用户管理:对于共享云的团队,Horizon 的 Keystone 服务允许管理员管理用户、分配角色和设置配额。这对于控制资源分配和有效管理成本至关重要。
OpenStack 中不断增长的人工智能支持
随着 AI 使用的扩展,OpenStack 将继续发展以满足新的需求。这种进步取决于社区协作,特别是来自 AI 用户和云操作员的反馈。
协作的一种关键方式是通过 OpenInfra AI 工作组。OpenInfra AI WG 的目标是呈现用例并增强 OpenInfra 项目支持 AI 工作负载的方式。该工作组向 OpenInfra 社区开放,以确保代表所有观点。会议会定期举行,通常侧重于案例研究演示和协作项目,例如白皮书。要参与其中,订阅邮件列表。
来塑造 OpenStack 上的 AI 未来!
生产案例研究和参考架构
中国移动
中国移动云(ECloud):以强大的计算能力赋能企业 AI 创新和应用
作为 OpenInfra 基金会的金级会员和中国移动通信集团有限公司旗下的云计算品牌,ECloud 致力于为全球企业提供安全、可靠和高性能的云和 AI 解决方案。凭借中国移动强大的网络资源和专有技术,ECloud 积极支持全球数字经济,并赋能企业实现智能化转型。在人工智能 (AI) 发展蓬勃的浪潮中,ECloud 通过其全球基础设施、多计算架构以及 OpenStack 和 COCA 计算原生平台的双重技术支撑,为各种 AI 工作负载提供强大而可靠的支持。
以领先世界的计算能力驱动教育和产业的智能化转型
ECloud 已在国内和国际部署计算资源,以确保 AI 应用所需的低延迟、高可靠性网络连接。ECloud 在中国境内建立了“4+N+31+X”分布式计算架构,总计算能力达到 20 EFlops。ECloud 实现对 CPU、DPU 和 GPU 计算架构的统一管理和智能调度,为 AI 训练和推理提供强大的异构计算能力支持。ECloud 已在德国和巴基斯坦等国际市场推出公有云、私有云和边缘云平台,并完成了“公有云 + 私有云 + 边缘云”全系列产品的全球推广。ECloud 独立开发了 AI 驱动的多语言管理平台,具有统一架构、敏捷交付、轻量级部署和运营能力。
案例 1:集群化计算能力助力中国某省构建 AI 产业大模型
ECloud 与合作伙伴签订战略协议,利用当地清洁能源和气候优势共同开发大模型 AI 应用。该项目采用高性能裸金属服务器集群,为 AI 大模型的训练和推理提供极致性能支持,成功推动人工智能技术在智能产业、智慧医疗、文化旅游等领域的实施。ECloud 已成为推动当地数字经济的新引擎。
案例 2:专用计算能力赋能中国能源制造企业启动数字化智能战略规划
ECloud 帮助客户通过构建具有应用和平台能力的平台来启动数字化和智能战略举措。为了支持这些智能计算场景并满足快速计算能力交付需求,ECloud 通过公有云资源与专用计算能力相结合的混合方式提供资源,采用“租用而非构建”模式。这成为中国能源和化工行业的标杆案例,赋能客户实施其“数字化和智能中国”战略。
案例 3:助力建立某海外云
ECloud 促进了某海外云的实施,为该地区数字化转型和 AI 技术发展提供了关键的基础设施支持。该地区的公有云品牌采用双区域本地池构建,实现一地双站布局,并被选为中国与上海合作组织国家之间的数字经济合作典范案例。
ECloud 的 AI 技术优势
随着企业积极采用人工智能技术,普遍遇到的挑战包括有限的计算资源、数据安全风险和复杂的技术实施。ECloud 建立在其自研 COCA 计算能力原生平台之上,建立涵盖三个维度的全面能力:计算能力、安全性和应用。这有助于企业一站式实现无缝 AI 转型。
在计算能力层面,ECloud 利用其磐石服务器实现与主流 CPU 平台和 NVIDIA 等主流异构芯片的兼容性。这实现了从 AI 推理到 4K 渲染的各种场景的真正“一云通用”能力。其专有的 DPU 芯片通过硬件级虚拟化进一步加速性能,将第六代云主机性能提升高达 80%。通用计算产品以 55% 的每核成本降低,显着降低了中小企业部署 AI 应用的门槛。这使得传统的 IT 预算能够释放出非凡的计算能力。
利用 COCA 计算能力原生架构,ECloud 支持亚秒级加载和 DeepSeek-R1 等万亿参数模型的有效运行,实现跨 GPU 生态系统的零成本迁移。结合 ECloud 的 AI 数据湖和超快速文件存储,企业可以有效地处理多模态数据和训练模型,迅速抢占 AI 创新制高点。这真正实现了“计算能力与 AI 的深度共鸣”,重塑了大模型时代的新基础设施。
在调度层,ECloud 利用其全国计算网络基础设施和开源 OpenStack 基础创新了 Grand Cloud 混合弹性计算系统和计算网络大脑。利用 AI 算法实时感知业务需求和资源状态,动态推荐最佳资源组合。这实现了数千台机器规模的分钟级快速交付最佳计算能力,使智能计算能力像水和电力一样随时可用。在安全性和可靠性方面,ECloud 主机服务提供高达 99.995% 的 SLA。它构建了覆盖整个链条的计算能力全面健康视图,实现了故障预测和无缝恢复,同时支持全机备份和跨域灾难恢复,为政府事务和金融等高度敏感场景提供全方位保护,确保 AI 时代的企业连续性和数据安全。
目前,ECloud 在 CNOCS、Linux 和 Kube-OVN 等主要开源社区中名列前茅,展示了其深厚的技术实力和对开放协作和创新的承诺。致力于推动智能时代,ECloud 利用全球领先的计算基础设施、开放兼容的多架构系统为企业提供全栈 AI 支持——从训练到推理,从芯片到框架。无论是在国内构建分布式计算网络,还是在海外推进多云战略,ECloud 都坚持其“计算能力无处不在,智能随需而至”的愿景,帮助各行各业高效、安全、经济地拥抱人工智能。
ECloud 致力于成为世界一流的云服务提供商,不断增强 COCA 平台和磐石服务器等技术能力,同时扩展其全球计算能力网络和生态系统协作优势。ECloud 将与更多企业和合作伙伴合作,共同推进人工智能技术的规模化实施,并推动产业智能化升级。
选择 ECloud 就是选择全面的 AI 转型战略,并选择高性能云服务合作伙伴。让我们携手 ECloud,通过强大的计算能力释放创新潜力,共同拥抱智能未来。
FPT Smart Cloud

FPT Smart Cloud 通过 AI Factory 向用户提供一系列可定制的 OpenStack 服务:
- 基于 OpenStack Ironic 的 GPU H100/H200 裸金属即服务
- 通过 PCI-Passthrough 和 SRIOV 技术提供的 GPU/vGPU 云实例
- 使用 OpenStack Nova 的云工作站/桌面
- 使用 OpenStack Magnum 配置 GPU Kubernetes 引擎
- 基于 GPU K8S 引擎和 NVIDIA MIG 技术的 GPU 容器即服务
- 在一个集群中,具有不同显卡型号或多个显卡专用于单个 VM 的自助服务能力
- OpenStack 插件,即用型服务,包括负载均衡 (Octavia)、GPU VM 自动扩展 (Senlin) 和存储备份 (Cinder)
- FPT Cloud Desktop 通过集成 OpenStack 和 OpenUDS 实现 GPU 加速
- 在支持这些用例的基础设施技术方面,FPT Smart Cloud 采用了开源基础设施软件,特别是 OpenStack,原因如下:
- 定制化的灵活性
- 广泛的工具集,可支持硬件优化/加速和卸载 (NUMA、SRIOV、CPU PIN、多队列 VIF)
- 成熟的 AI 应用云生态系统 (VM、存储、自动扩展、自动化、负载均衡器、Kubernetes 配置表单)
- 支持 GPU 工作负载的多种模型 (VM PCI 直通、vGPU、MIG)
OpenStack 为 AI 工作负载提供了无与伦比的灵活性和定制性,尤其是在大规模情况下。它提供了广泛的选项来加速 GPU 性能并优化 AI 任务的基础设施。与 VMware 等传统闭源平台不同,OpenStack 赋予用户开放创新、社区驱动的开发以及针对 AI 需求量身定制的深度集成能力。
随着 AI 工作负载和技术的快速发展,像 OpenStack 这样的开源平台与专有企业云解决方案相比,能够更快地采用并缩短上市时间。生态系统的开放性,加上强大的硬件兼容性和可扩展的架构,使 OpenStack 成为 AI 基础设施更强大、更面向未来的基础。
Rackspace
OpenStack 在 Rackspace Technology 的 AI 战略中发挥着基础性作用,作为使 AI 创新成为可能的灵活、开放的基础设施层。通过 FAIR(Rackspace 的 AI Foundry),我们开发了一种负责任且有效地利用 AI 创新的方法。通过将 FAIR 的框架与 OpenStack 的可扩展性和开放性相结合,Rackspace 使客户能够安全高效地构建、部署和扩展 AI 工作负载。
GPU 支持
Rackspace 正在以多种方式利用 OpenStack 来交付 GPU 启用的解决方案
GPU 直通实例在我们的 OpenStack Flex 公有云以及我们的 OpenStack Business 混合云选项中均可用。在此功能的基础上,Rackspace Spot 提供托管的 GPU 启用的 Kubernetes 集群,非常适合容器化的 AI 工作负载。
Rackspace Spot 和 OpenStack Flex 的结合提供了对多种 GPU 类型的访问
- A30
- H100
- P40
很快,Rackspace Spot Enterprise 将能够在 OpenStack 之上为本地部署启用相同的托管 Kubernetes 集群功能,以支持容器化的 AI GPU 工作负载。
AI 专用产品
Rackspace Private Cloud AI 有助于在安全的环境中利用 AI 的力量,利用完整的 AI 软件堆栈和最新的 AI 优化硬件。
OpenStack 是向客户交付 AI 价值的关键部分。
OpenStack 用于我们的本地 Rackspace AI Anywhere 解决方案的控制平面。
AI 启用的 OpenStack
目前正在开发中,Rackspace 正在研究利用 Agentic AI 来实现云部署的运营效益和控制。通过我们积累的大量云数据、多年的运营经验以及 OpenStack 100% API 驱动的特性,Rackspace 旨在利用 AI 提供的洞察力和能动性,简化和自动化未来的 OpenStack 部署。
StackHPC - 6G AI Sweden
为 AI 工作负载提供的具有竞争力的基础设施是当今市场上性能最密集的可用基础设施之一。充分利用这种基础设施的潜力对于最大化硬件和软件投资的回报至关重要。
6G AI Sweden 的目标是为瑞典公司提供世界一流的 AI 能力,同时保持绝对的数据主权。为了实现这一目标,6G AI Sweden 选择了一种以 OpenStack 为中心的技术堆栈、Kubernetes 和开放基础设施解决方案,这些解决方案由 StackHPC 设计和部署。
硬件基础设施
计算
6G AI Sweden 的 AI 计算节点基于 NVIDIA “HGX” 参考架构
- 8 个 NVIDIA H200 GPU
- 8 个 400G NDR InfiniBand 高速网络
- 8 个本地 NVME 存储,本地于每个 GPU
- 2 个 200G Bluefield-3 以太网智能网卡
- 1G 以太网用于配置
- 专用 BMC 连接
一个专用的超visor 资源提供虚拟化计算,用于控制、监控和支持功能。
网络
6G AI Sweden 的高速 InfiniBand 织物使用 NVIDIA 的 400G NDR InfiniBand 实现,作为多轨网络互连 H200 GPU 设备。
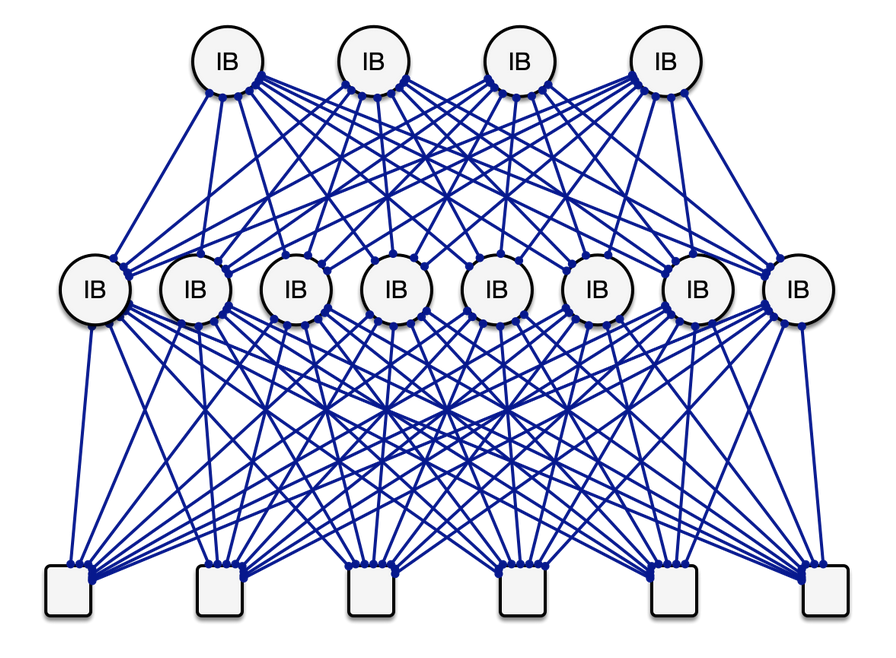
一个示例 InfiniBand 网络织物,采用胖树拓扑,其中每个计算节点(底行)具有 8 个 InfiniBand 链路。多个链路可能存在于交换机之间,以产生非阻塞网络,在该网络中,所有节点可以在所有链路以全网络带宽的情况下同时通信。
基础设施的以太网网络基于 800G NVIDIA 交换机和网络织物,分解为 2x200G 绑定链路,连接计算节点和存储。
此外,还存在用于服务器配置、控制和电源/管理的管理以太网网络。
存储
6G AI Sweden 选择 VAST data 的高性能存储,能够提供对象、块和文件存储服务,并具有多租户隔离。
OpenStack 云基础设施
对于 AI 用例,OpenStack 的一个重要优势是它对裸金属、虚拟化和容器化的原生支持,所有这些都包含在相同的可重新配置基础设施中。OpenStack 的多租户模型和细粒度策略也非常适合 AI 基础设施的云原生服务提供商。
OpenStack Kayobe 使用基础设施即代码原则配置云。硬件配置、操作系统配置和网络配置都使用单个版本控制源存储库定义。OpenStack 服务通过 Kolla-Ansible 部署和配置。Kayobe 对基础设施的精确配置和管理因其灵活性、易用性和内置对高性能计算的支持而被选中。
对于 AI 计算节点,使用 OpenStack Ironic 创建了裸金属云基础设施。服务器使用 Ironic 的虚拟介质驱动程序部署,简化了引导过程,并避免了在部署期间需要 DHCP 和 iPXE 步骤。
多租户隔离是 6G AI 商业模式的关键要求。裸金属计算基础设施被配置到客户端租户中。Ironic 实现了在多租户环境中有效管理裸金属的功能,例如部署和清理的可配置步骤。
Neutron 网络使用 OVN 实现。多租户网络隔离使用虚拟租户网络实现,连接租户的 VM 和裸金属计算节点。
- 以太网中的租户网络是 VLAN,可实现裸金属和虚拟化计算资源之间的轻松互通。多租户以太网网络隔离使用 networking-generic-switch Neutron 驱动程序实现。用于清理和配置的单独网络将基础设施生命周期的其他阶段安全地置于幕后。
- InfiniBand 中的租户网络是分区,分配为分区密钥 (pkeys),并与 NVIDIA 的 Unified Fabric Manager (UFM) 集成的 networking-mellanox Neutron 驱动程序进行管理。
VAST Data 存储为 Glance、Cinder 和 Manila 提供后端服务,以及为租户工作负载提供的 S3 对象存储。对于虚拟化基础设施,块存储使用 VAST Data 新开发的 NVME-over-TCP Cinder 驱动程序实现。
文件存储使用 VAST Data 的 Manila 驱动程序实现,提供多租户编排的高性能文件存储,所有这些都使用行业标准 NFS 的最新优化。
Azimuth 和 Kubernetes
世界一流的 AI 能力需要世界一流的计算平台,建立在高性能基础设施之上,使用户能够直接进入 AI 生产力。StackHPC 是 Azimuth Cloud Portal 的主要开发人员和保管人,Azimuth Cloud Portal 是一个直观的门户,用于以自助服务方式提供计算平台。Azimuth 是免费且开源的软件,StackHPC 提供部署、配置、扩展、维护和支持该项目的服务。
Azimuth 中的平台创建涉及从策划的基础设施即代码配方中进行选择,这些配方已准备好配置并与底层基础设施深度集成。
大多数 AI 工作负载作为容器化应用程序使用 Kubernetes 部署。在 6G AI 云中,Kubernetes 集群跨越 VM 资源和裸金属 AI 计算节点。Kubernetes 可以作为 Azimuth 中的平台或通过 FluxCD 的 GitOps 驱动的工作流程部署。在两种情况下,Kubernetes 都使用行业标准 Cluster API 部署并使用 Helm 配置。6G AI Sweden 提供 NVIDIA NGC Catalog 的容器化软件应用程序和 Helm 图表。
ZTE
1. ZTE 的 AI 基础设施管理架构和解决方案
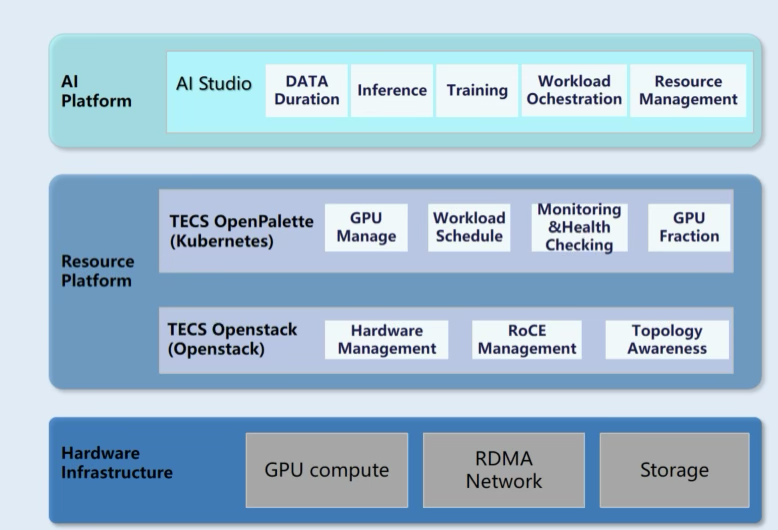
架构:ZTE 发布了三层软件架构来解决 AI 问题
- 硬件基础设施
- 资源平台
- AI 平台。
ZTE 提供全套 AI 硬件设备。包括 GPU 服务器、RDMA 交换机和高性能存储设备。在软件层面,该解决方案由 OpenStack、Kubernetes 和 ML 层组成。
OpenStack 负责管理基础设施硬件,包括服务器、网络设备和存储对接。Kubernetes 是上层。结合 K8S 平台作为计算能力调度基础。添加与调度相关的组件以增强 AI 调度能力。AI Studio 是 ZTE 自研的 AI 平台,作为工作负载管理层。提供机器学习所需的工具链。完成模型开发、预训练、推理部署和应用开发等各种大型模型任务。
2. ZTE AI 基础设施管理案例
电信网络云
客户问题: 满足推理需求,满足训练需求,以及运维策略
解决方案: 中心训练,边缘推理。增强运维。
IT 资源池
OpenStack 分发虚拟机 + ironic 裸金属。
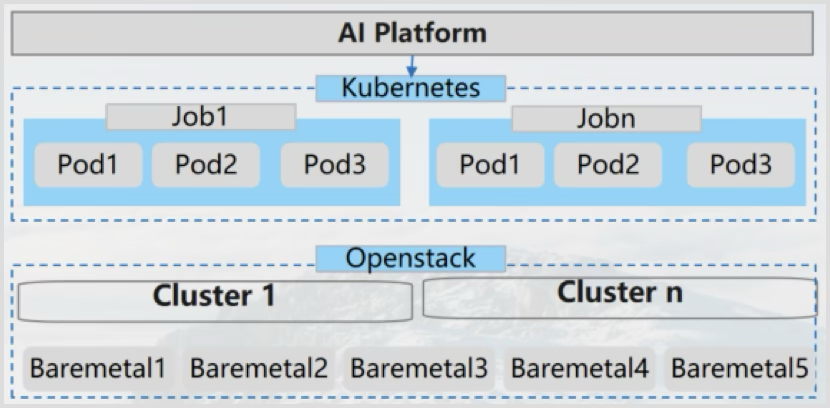
训练场景: 调度裸金属以实现模型训练。
推理场景: 应用程序在虚拟机上运行,模型在裸金属上运行。
作者
Amine Badaoui, Keshav Bareja, , Sylvain Bauza, Mark Collier, Dmitry Galkin, Artem Goncharov, Thel Gunther, Petr Kubica, Li Liu, Jimmy McArthur, Mike McDonough, Kendall Nelson, Mauro Oddi, Kyunghwan Oh, Tatiana Ovchinnikova, Allison Price, Sang Tran Quoc, Adrian Reza, Chris Sibbitt, Stig Telfer & Steve Westmoreland